 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation
Paper and Code
Mar 10, 2022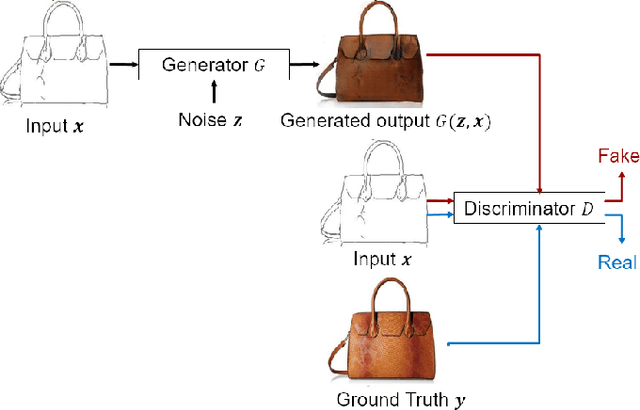
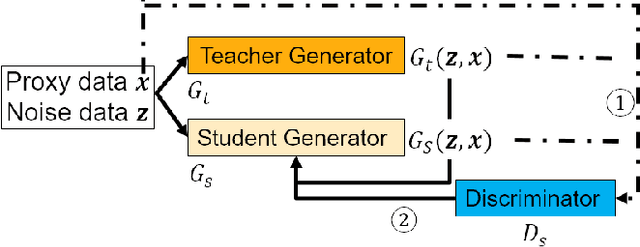
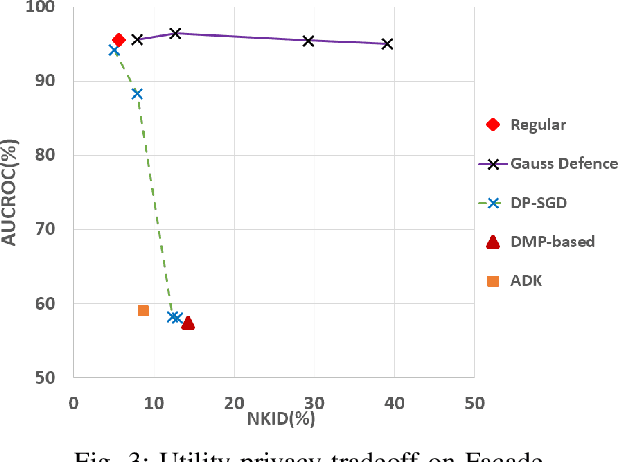
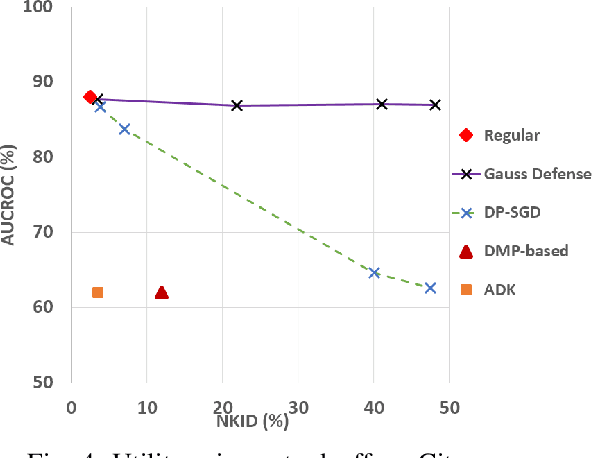
Image-to-image translation models are shown to be vulnerable to the Membership Inference Attack (MIA), in which the adversary's goal is to identify whether a sample is used to train the model or not. With daily increasing applications based on image-to-image translation models, it is crucial to protect the privacy of these models against MIAs. We propose adversarial knowledge distillation (AKD) as a defense method against MIAs for image-to-image translation models. The proposed method protects the privacy of the training samples by improving the generalizability of the model. We conduct experiments on the image-to-image translation models and show that AKD achieves the state-of-the-art utility-privacy tradeoff by reducing the attack performance up to 38.9% compared with the regular training model at the cost of a slight drop in the quality of the generated output images. The experimental results also indicate that the models trained by AKD generalize better than the regular training models. Furthermore, compared with existing defense methods, the results show that at the same privacy protection level, image translation models trained by AKD generate outputs with higher quality; while at the same quality of outputs, AKD enhances the privacy protection over 30%.