 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeet in the Middle: A New Pre-training Paradigm
Paper and Code
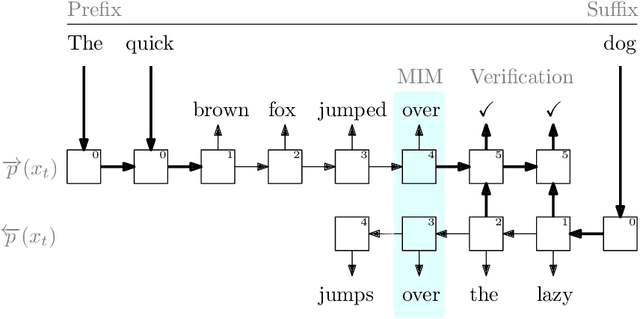
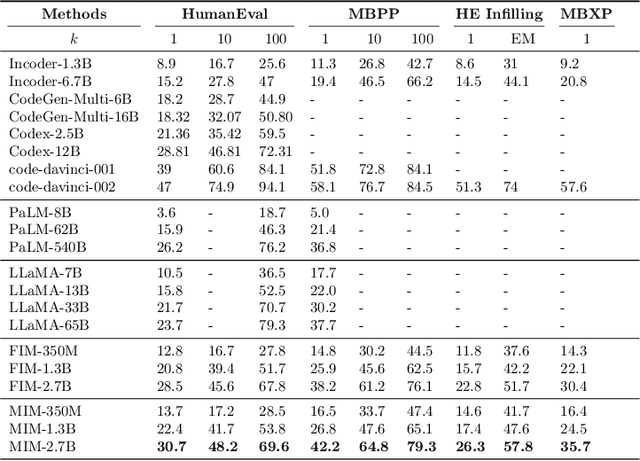
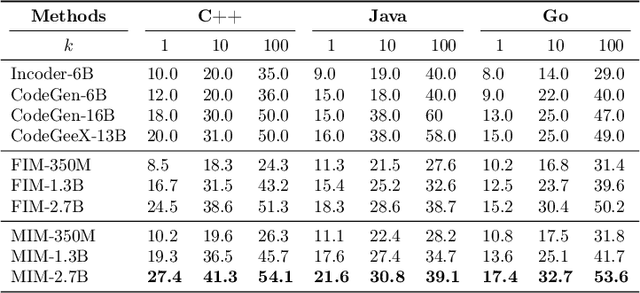
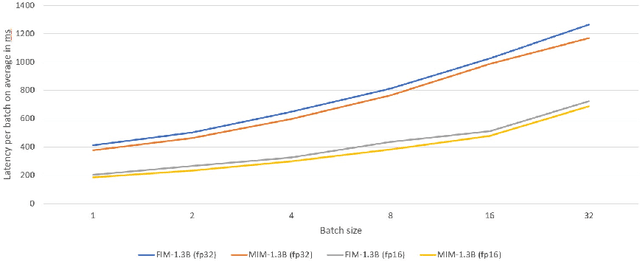
Most language models (LMs) are trained and applied in an autoregressive left-to-right fashion, assuming that the next token only depends on the preceding ones. However, this assumption ignores the potential benefits of using the full sequence information during training, and the possibility of having context from both sides during inference. In this paper, we propose a new pre-training paradigm with techniques that jointly improve the training data efficiency and the capabilities of the LMs in the infilling task. The first is a training objective that aligns the predictions of a left-to-right LM with those of a right-to-left LM, trained on the same data but in reverse order. The second is a bidirectional inference procedure that enables both LMs to meet in the middle. We show the effectiveness of our pre-training paradigm with extensive experiments on both programming and natural language models, outperforming strong baselines.