 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVisionLlama: Leveraging Pre-Trained Large Language Model Layers to Enhance Medical Image Segmentation
Paper and Code
Oct 03, 2024

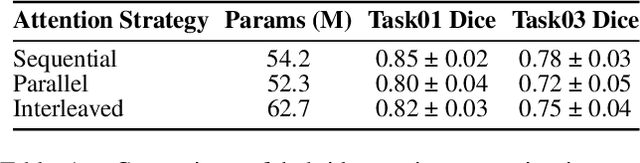
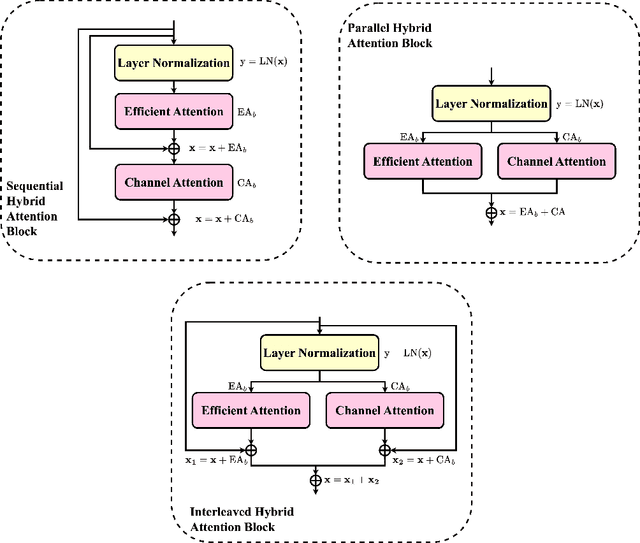
Large Language Models (LLMs), known for their versatility in textual data, are increasingly being explored for their potential to enhance medical image segmentation, a crucial task for accurate diagnostic imaging. This study explores enhancing Vision Transformers (ViTs) for medical image segmentation by integrating pre-trained LLM transformer blocks. Our approach, which incorporates a frozen LLM transformer block into the encoder of a ViT-based model, leads to substantial improvements in segmentation performance across various medical imaging modalities. We propose a Hybrid Attention Mechanism that combines global and local feature learning with a Multi-Scale Fusion Block for aggregating features across different scales. The enhanced model shows significant performance gains, including an average Dice score increase from 0.74 to 0.79 and improvements in accuracy, precision, and the Jaccard Index. These results demonstrate the effectiveness of LLM-based transformers in refining medical image segmentation, highlighting their potential to significantly boost model accuracy and robustness. The source code and our implementation are available at: https://bit.ly/3zf2CVs