 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Field Multi-Agent Reinforcement Learning: A Decentralized Network Approach
Paper and Code
Aug 05, 2021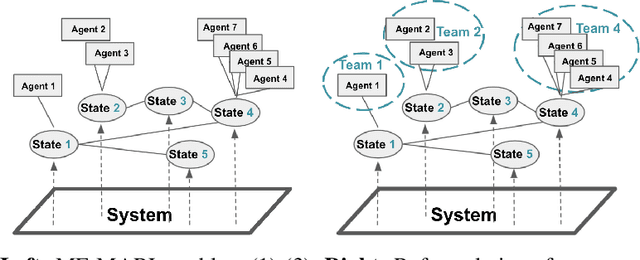
One of the challenges for multi-agent reinforcement learning (MARL) is designing efficient learning algorithms for a large system in which each agent has only limited or partial information of the entire system. In this system, it is desirable to learn policies of a decentralized type. A recent and promising paradigm to analyze such decentralized MARL is to take network structures into consideration. While exciting progress has been made to analyze decentralized MARL with the network of agents, often found in social networks and team video games, little is known theoretically for decentralized MARL with the network of states, frequently used for modeling self-driving vehicles, ride-sharing, and data and traffic routing. This paper proposes a framework called localized training and decentralized execution to study MARL with network of states, with homogeneous (a.k.a. mean-field type) agents. Localized training means that agents only need to collect local information in their neighboring states during the training phase; decentralized execution implies that, after the training stage, agents can execute the learned decentralized policies, which only requires knowledge of the agents' current states. The key idea is to utilize the homogeneity of agents and regroup them according to their states, thus the formulation of a networked Markov decision process with teams of agents, enabling the update of the Q-function in a localized fashion. In order to design an efficient and scalable reinforcement learning algorithm under such a framework, we adopt the actor-critic approach with over-parameterized neural networks, and establish the convergence and sample complexity for our algorithm, shown to be scalable with respect to the size of both agents and states.