 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge!MDP Playground: Meta-Features in Reinforcement Learning
Paper and Code



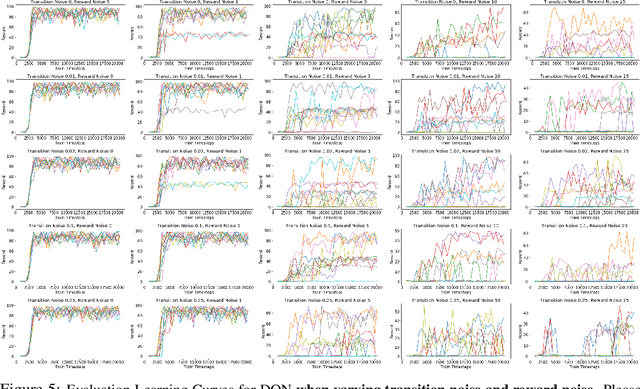
Reinforcement Learning (RL) algorithms usually assume their environment to be a Markov Decision Process (MDP). Additionally, they do not try to identify specific features of environments which could help them perform better. Here, we present a few key meta-features of environments: delayed rewards, specific reward sequences, sparsity of rewards, and stochasticity of environments, which may violate the MDP assumptions and adapting to which should help RL agents perform better. While it is very time consuming to run RL algorithms on standard benchmarks, we define a parameterised collection of fast-to-run toy benchmarks in OpenAI Gym by varying these meta-features. Despite their toy nature and low compute requirements, we show that these benchmarks present substantial difficulties to current RL algorithms. Furthermore, since we can generate environments with a desired value for each of the meta-features, we have fine-grained control over the environments' difficulty and also have the ground truth available for evaluating algorithms. We believe that devising algorithms that can detect such meta-features of environments and adapt to them will be key to creating robust RL algorithms that work in a variety of different real-world problems.