 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy, Word-Frequency, Chinese Characters, and Multiple Meanings
Paper and Code
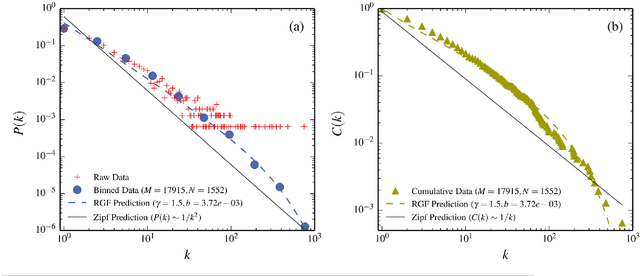
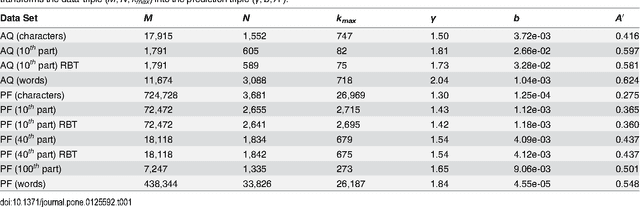
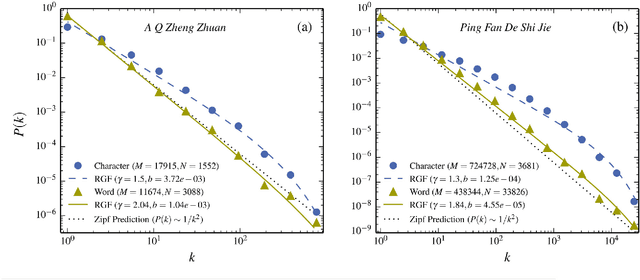
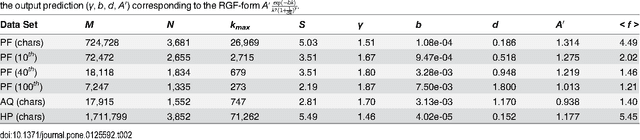
The word-frequency distribution of a text written by an author is well accounted for by a maximum entropy distribution, the RGF (random group formation)-prediction. The RGF-distribution is completely determined by the a priori values of the total number of words in the text (M), the number of distinct words (N) and the number of repetitions of the most common word (k_max). It is here shown that this maximum entropy prediction also describes a text written in Chinese characters. In particular it is shown that although the same Chinese text written in words and Chinese characters have quite differently shaped distributions, they are nevertheless both well predicted by their respective three a priori characteristic values. It is pointed out that this is analogous to the change in the shape of the distribution when translating a given text to another language. Another consequence of the RGF-prediction is that taking a part of a long text will change the input parameters (M, N, k_max) and consequently also the shape of the frequency distribution. This is explicitly confirmed for texts written in Chinese characters. Since the RGF-prediction has no system-specific information beyond the three a priori values (M, N, k_max), any specific language characteristic has to be sought in systematic deviations from the RGF-prediction and the measured frequencies. One such systematic deviation is identified and, through a statistical information theoretical argument and an extended RGF-model, it is proposed that this deviation is caused by multiple meanings of Chinese characters. The effect is stronger for Chinese characters than for Chinese words. The relation between Zipf's law, the Simon-model for texts and the present results are discussed.