 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Exploration of Neural Machine Translation Architectures
Paper and Code
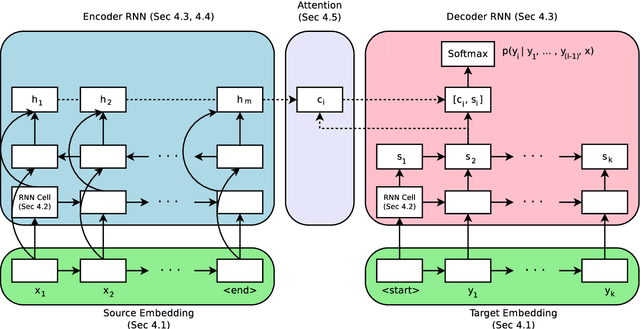


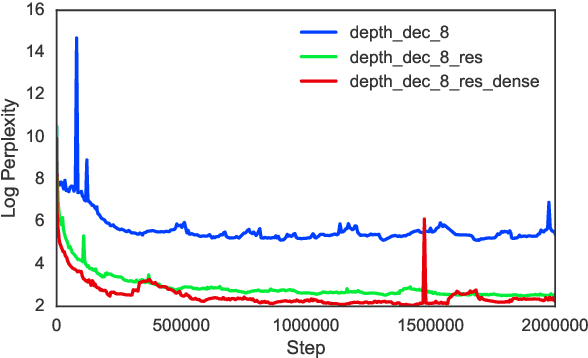
Neural Machine Translation (NMT) has shown remarkable progress over the past few years with production systems now being deployed to end-users. One major drawback of current architectures is that they are expensive to train, typically requiring days to weeks of GPU time to converge. This makes exhaustive hyperparameter search, as is commonly done with other neural network architectures, prohibitively expensive. In this work, we present the first large-scale analysis of NMT architecture hyperparameters. We report empirical results and variance numbers for several hundred experimental runs, corresponding to over 250,000 GPU hours on the standard WMT English to German translation task. Our experiments lead to novel insights and practical advice for building and extending NMT architectures. As part of this contribution, we release an open-source NMT framework that enables researchers to easily experiment with novel techniques and reproduce state of the art results.