 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Enhanced Extracted Email Features Tailored for Cosine Distance
Paper and Code
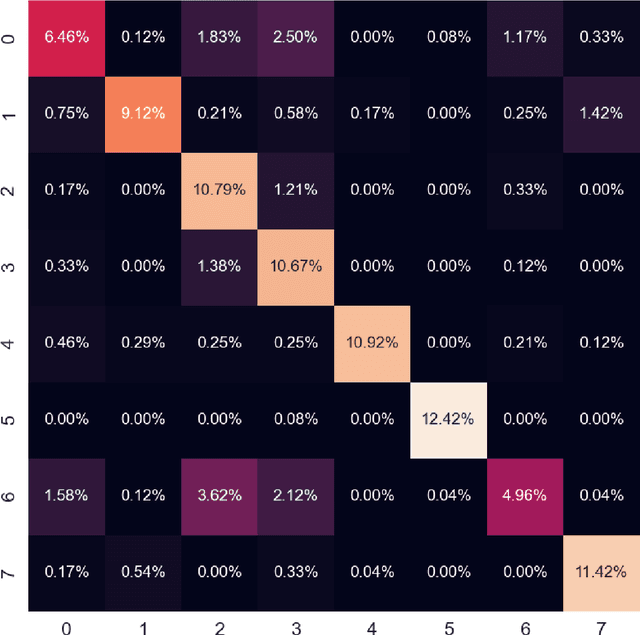
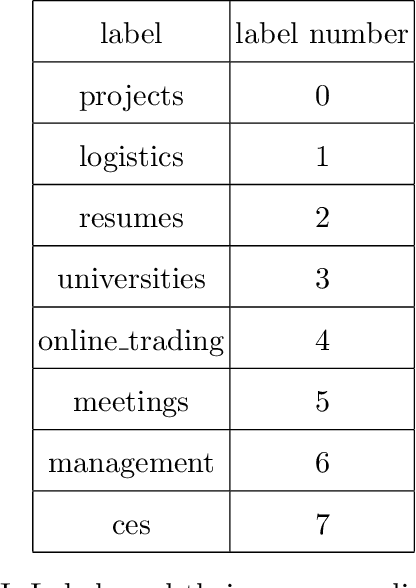
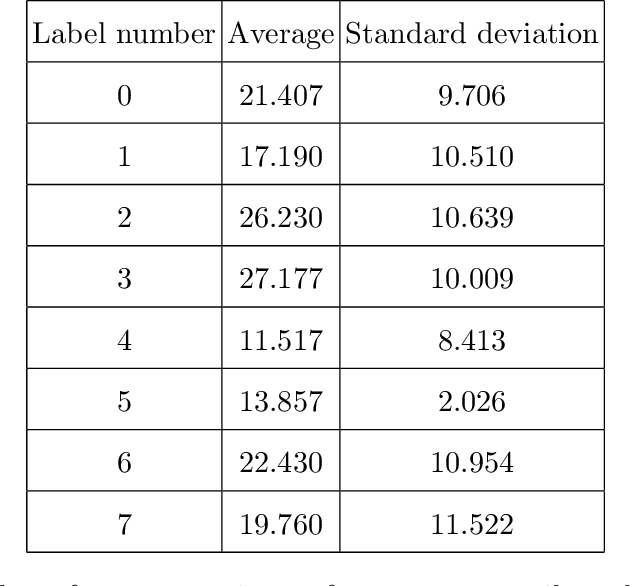
In this paper, the process of converting the Enron email dataset (the version cited in the preprint) to thousands of features per email for a selected set of 2400 labelled emails is explained and evaluated. The final features are tailored for Cosine distance so that the Cosine distance invertly reflect the number of top indicative words of each email that are common between the two emails in an explainable normalized fashion. The labelling is based on the leaf folder name in the Enron email dataset (the version cited in the preprint) folders tree and the 2400 emails selected consist 300 emails for each of the 8 labels. The evaluation is based on the accuracy of a k nearest neighbours majority voting classification using Cosine distance. In addition to KNN majority voting classification accuracy and confusion matrix, some statistics for the process is reported. The KNN majority voting classification accuracy using Cosine distance is 76.75% which shows at least some level of success given the 8 labels involved. The result of conversion is 48557 features per selected email out of which exactly 40 features per email are non-zero. The result of conversion is a data set named MeeefTCD (Massive Enhanced Extracted Email Features Tailored for Cosine Distance) available at https://web.cs.dal.ca/~barahimi/data-sets/meeeftcd/ and on a github repository mentioned in this paper.