 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Matrix Multiplication for Emergent Sparsity
Paper and Code
Feb 21, 2024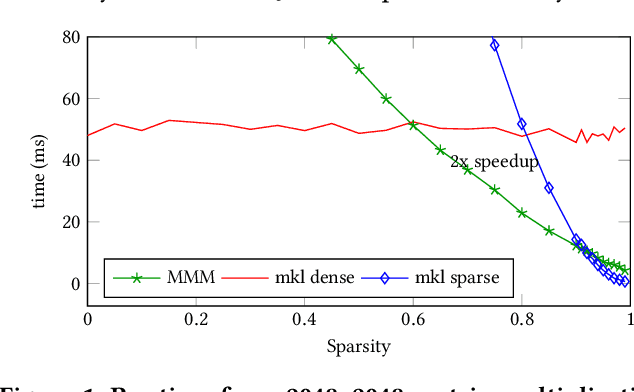

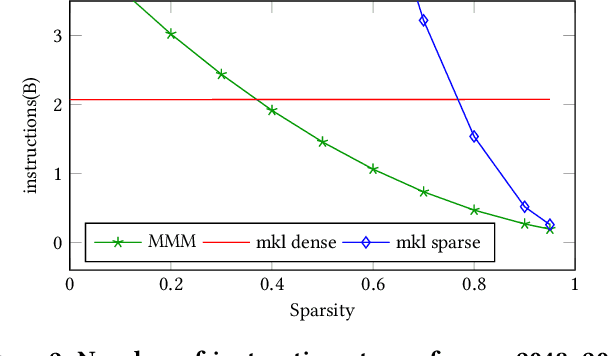
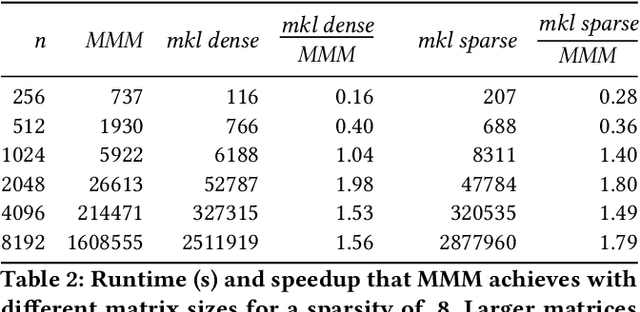
Artificial intelligence workloads, especially transformer models, exhibit emergent sparsity in which computations perform selective sparse access to dense data. The workloads are inefficient on hardware designed for dense computations and do not map well onto sparse data representations. We build a vectorized and parallel matrix-multiplication system A X B = C that eliminates unnecessary computations and avoids branches based on a runtime evaluation of sparsity. We use a combination of dynamic code lookup to adapt to the specific sparsity encoded in the B matrix and preprocessing of sparsity maps of the A and B matrices to compute conditional branches once for the whole computation. For a wide range of sparsity, from 60% to 95% zeros, our implementation performs fewer instructions and increases performance when compared with Intel MKL's dense or sparse matrix multiply routines. Benefits can be as large as 2 times speedup and 4 times fewer instructions.