 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Cricket: Using Forward and Inverse Reinforcement Learning to Model, Predict And Optimize Batting Performance in One-Day International Cricket
Paper and Code
Mar 07, 2021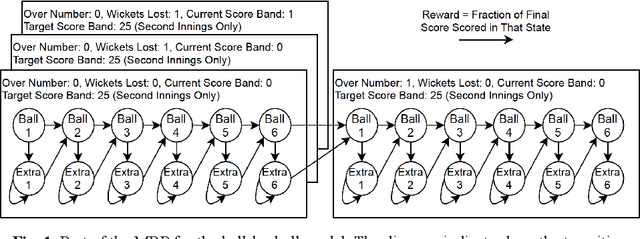
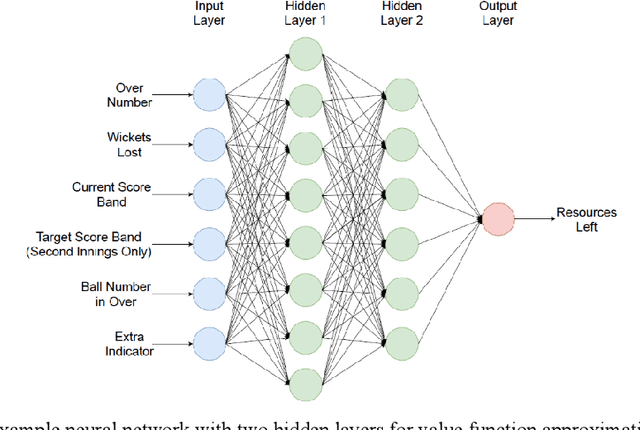
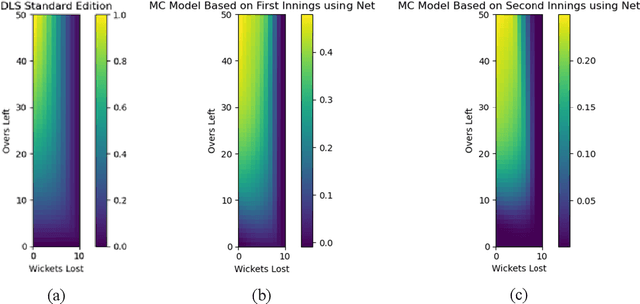
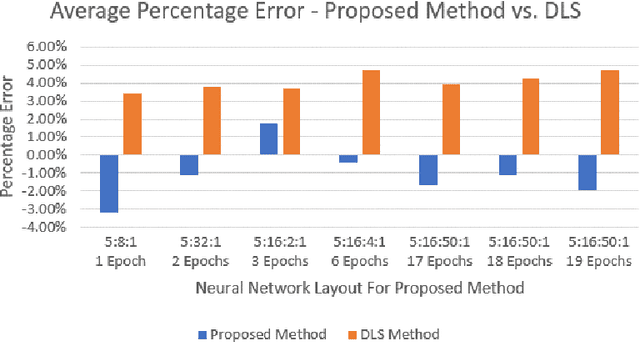
In this paper, we model one-day international cricket games as Markov processes, applying forward and inverse Reinforcement Learning (RL) to develop three novel tools for the game. First, we apply Monte-Carlo learning to fit a nonlinear approximation of the value function for each state of the game using a score-based reward model. We show that, when used as a proxy for remaining scoring resources, this approach outperforms the state-of-the-art Duckworth-Lewis-Stern method used in professional matches by 3 to 10 fold. Next, we use inverse reinforcement learning, specifically a variant of guided-cost learning, to infer a linear model of rewards based on expert performances, assumed here to be play sequences of winning teams. From this model we explicitly determine the optimal policy for each state and find this agrees with common intuitions about the game. Finally, we use the inferred reward models to construct a game simulator that models the posterior distribution of final scores under different policies. We envisage our prediction and simulation techniques may provide a fairer alternative for estimating final scores in interrupted games, while the inferred reward model may provide useful insights for the professional game to optimize playing strategy. Further, we anticipate our method of applying RL to this game may have broader application to other sports with discrete states of play where teams take turns, such as baseball and rounders.