 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation Model based on Non-parallel Corpus and Semi-supervised Transductive Learning
Paper and Code
May 22, 2014
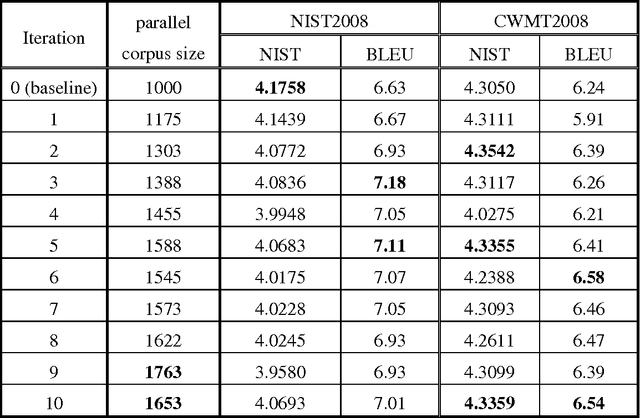
Although the parallel corpus has an irreplaceable role in machine translation, its scale and coverage is still beyond the actual needs. Non-parallel corpus resources on the web have an inestimable potential value in machine translation and other natural language processing tasks. This article proposes a semi-supervised transductive learning method for expanding the training corpus in statistical machine translation system by extracting parallel sentences from the non-parallel corpus. This method only requires a small amount of labeled corpus and a large unlabeled corpus to build a high-performance classifier, especially for when there is short of labeled corpus. The experimental results show that by combining the non-parallel corpus alignment and the semi-supervised transductive learning method, we can more effectively use their respective strengths to improve the performance of machine translation system.