 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation in Pronunciation Space
Paper and Code
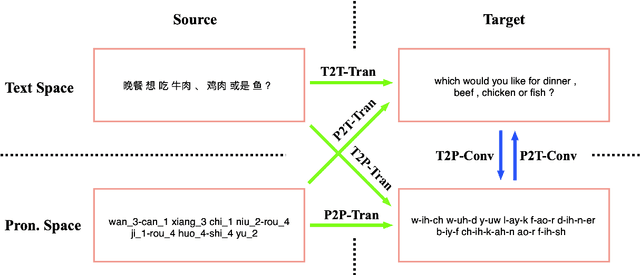



The research in machine translation community focus on translation in text space. However, humans are in fact also good at direct translation in pronunciation space. Some existing translation systems, such as simultaneous machine translation, are inherently more natural and thus potentially more robust by directly translating in pronunciation space. In this paper, we conduct large scale experiments on a self-built dataset with about $20$M En-Zh pairs of text sentences and corresponding pronunciation sentences. We proposed three new categories of translations: $1)$ translating a pronunciation sentence in source language into a pronunciation sentence in target language (P2P-Tran), $2)$ translating a text sentence in source language into a pronunciation sentence in target language (T2P-Tran), and $3)$ translating a pronunciation sentence in source language into a text sentence in target language (P2T-Tran), and compare them with traditional text translation (T2T-Tran). Our experiments clearly show that all $4$ categories of translations have comparable performances, with small and sometimes ignorable differences.