 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Training on a Real Processing-in-Memory System
Paper and Code
Jun 13, 2022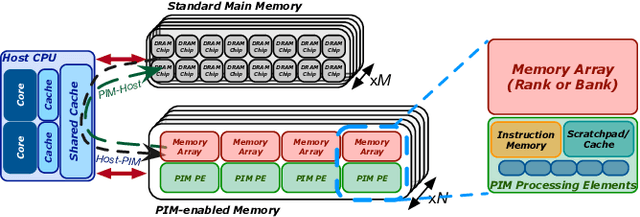
Training machine learning algorithms is a computationally intensive process, which is frequently memory-bound due to repeatedly accessing large training datasets. As a result, processor-centric systems (e.g., CPU, GPU) suffer from costly data movement between memory units and processing units, which consumes large amounts of energy and execution cycles. Memory-centric computing systems, i.e., computing systems with processing-in-memory (PIM) capabilities, can alleviate this data movement bottleneck. Our goal is to understand the potential of modern general-purpose PIM architectures to accelerate machine learning training. To do so, we (1) implement several representative classic machine learning algorithms (namely, linear regression, logistic regression, decision tree, K-means clustering) on a real-world general-purpose PIM architecture, (2) characterize them in terms of accuracy, performance and scaling, and (3) compare to their counterpart implementations on CPU and GPU. Our experimental evaluation on a memory-centric computing system with more than 2500 PIM cores shows that general-purpose PIM architectures can greatly accelerate memory-bound machine learning workloads, when the necessary operations and datatypes are natively supported by PIM hardware. To our knowledge, our work is the first one to evaluate training of machine learning algorithms on a real-world general-purpose PIM architecture.