 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Sentiment Prediction based on Hybrid Document Representation
Paper and Code
Nov 29, 2015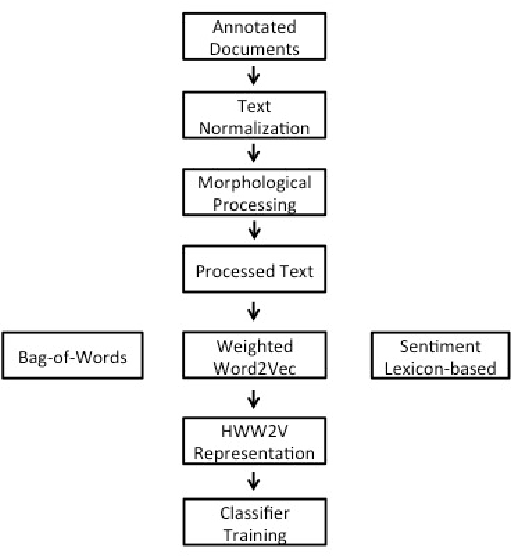
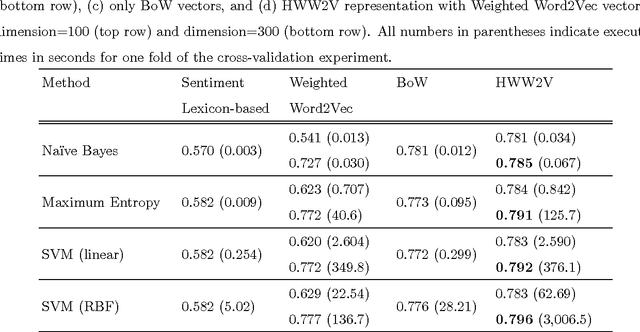
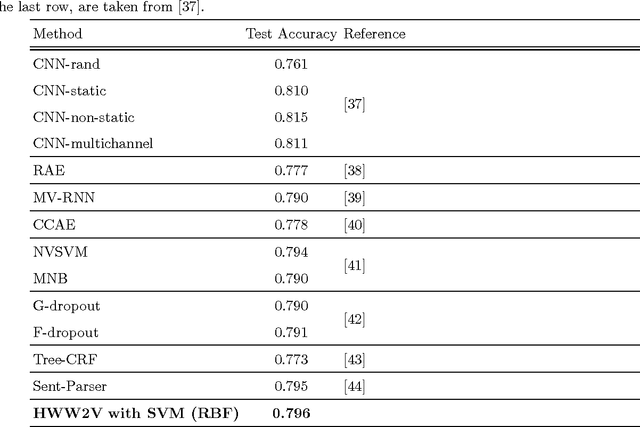
Automated sentiment analysis and opinion mining is a complex process concerning the extraction of useful subjective information from text. The explosion of user generated content on the Web, especially the fact that millions of users, on a daily basis, express their opinions on products and services to blogs, wikis, social networks, message boards, etc., render the reliable, automated export of sentiments and opinions from unstructured text crucial for several commercial applications. In this paper, we present a novel hybrid vectorization approach for textual resources that combines a weighted variant of the popular Word2Vec representation (based on Term Frequency-Inverse Document Frequency) representation and with a Bag- of-Words representation and a vector of lexicon-based sentiment values. The proposed text representation approach is assessed through the application of several machine learning classification algorithms on a dataset that is used extensively in literature for sentiment detection. The classification accuracy derived through the proposed hybrid vectorization approach is higher than when its individual components are used for text represenation, and comparable with state-of-the-art sentiment detection methodologies.