 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Structured Clinical Data
Paper and Code
Jul 21, 2017


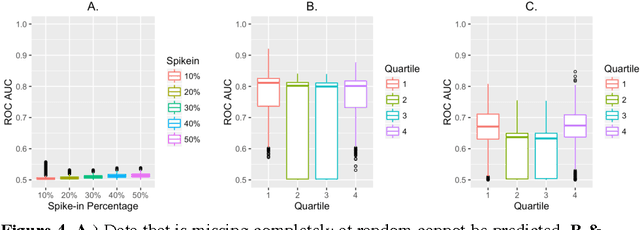
Research is a tertiary priority in the EHR, where the priorities are patient care and billing. Because of this, the data is not standardized or formatted in a manner easily adapted to machine learning approaches. Data may be missing for a large variety of reasons ranging from individual input styles to differences in clinical decision making, for example, which lab tests to issue. Few patients are annotated at a research quality, limiting sample size and presenting a moving gold standard. Patient progression over time is key to understanding many diseases but many machine learning algorithms require a snapshot, at a single time point, to create a usable vector form. Furthermore, algorithms that produce black box results do not provide the interpretability required for clinical adoption. This chapter discusses these challenges and others in applying machine learning techniques to the structured EHR (i.e. Patient Demographics, Family History, Medication Information, Vital Signs, Laboratory Tests, Genetic Testing). It does not cover feature extraction from additional sources such as imaging data or free text patient notes but the approaches discussed can include features extracted from these sources.