 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Capability: A standardized metric using case difficulty with applications to individualized deployment of supervised machine learning
Paper and Code
Feb 09, 2023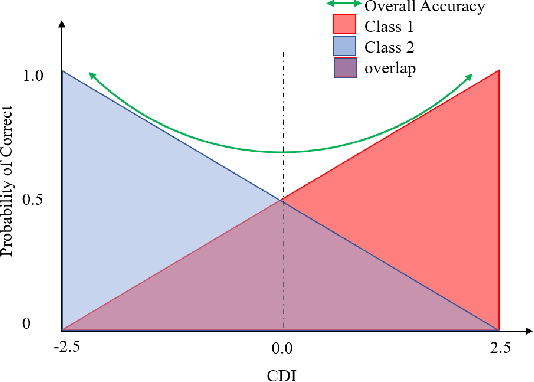
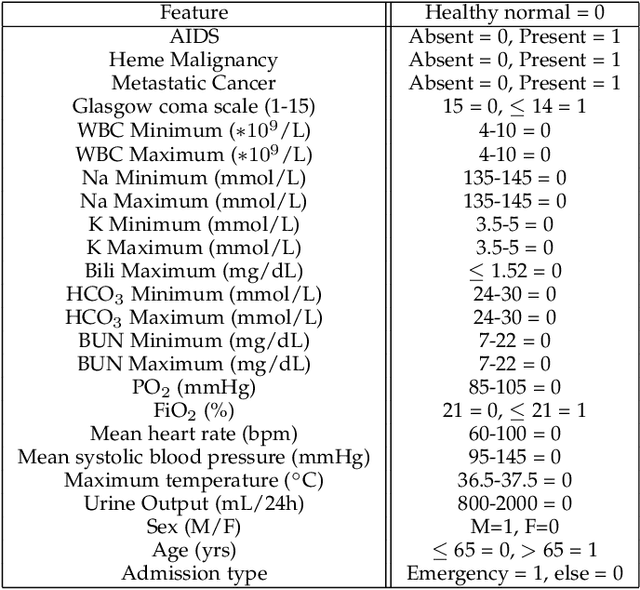
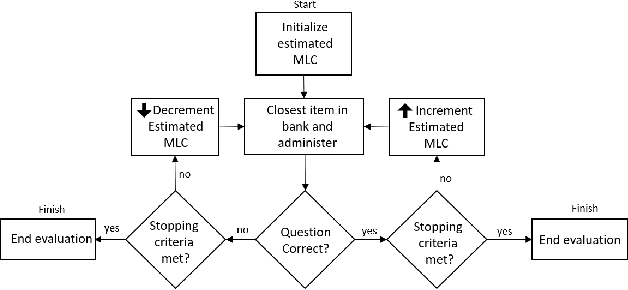

Model evaluation is a critical component in supervised machine learning classification analyses. Traditional metrics do not currently incorporate case difficulty. This renders the classification results unbenchmarked for generalization. Item Response Theory (IRT) and Computer Adaptive Testing (CAT) with machine learning can benchmark datasets independent of the end-classification results. This provides high levels of case-level information regarding evaluation utility. To showcase, two datasets were used: 1) health-related and 2) physical science. For the health dataset a two-parameter IRT model, and for the physical science dataset a polytonomous IRT model, was used to analyze predictive features and place each case on a difficulty continuum. A CAT approach was used to ascertain the algorithms' performance and applicability to new data. This method provides an efficient way to benchmark data, using only a fraction of the dataset (less than 1%) and 22-60x more computationally efficient than traditional metrics. This novel metric, termed Machine Learning Capability (MLC) has additional benefits as it is unbiased to outcome classification and a standardized way to make model comparisons within and across datasets. MLC provides a metric on the limitation of supervised machine learning algorithms. In situations where the algorithm falls short, other input(s) are required for decision-making.