Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning approach for text and document mining
Paper and Code
Jun 06, 2014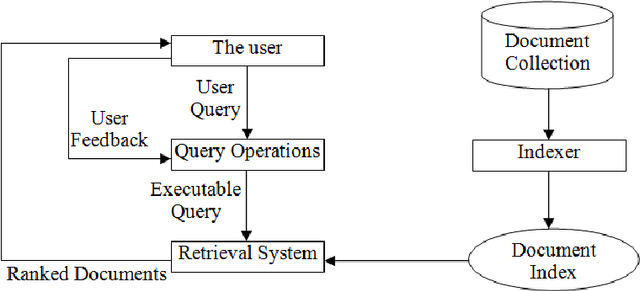
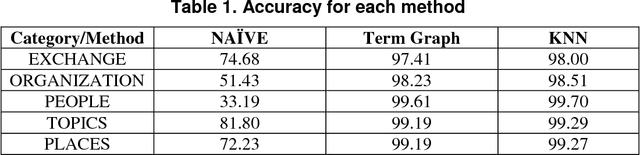
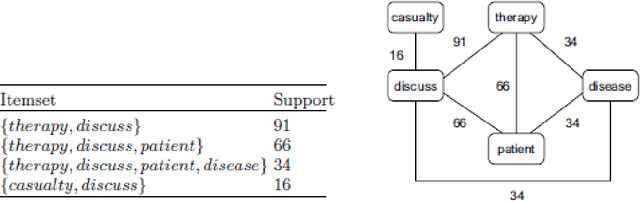
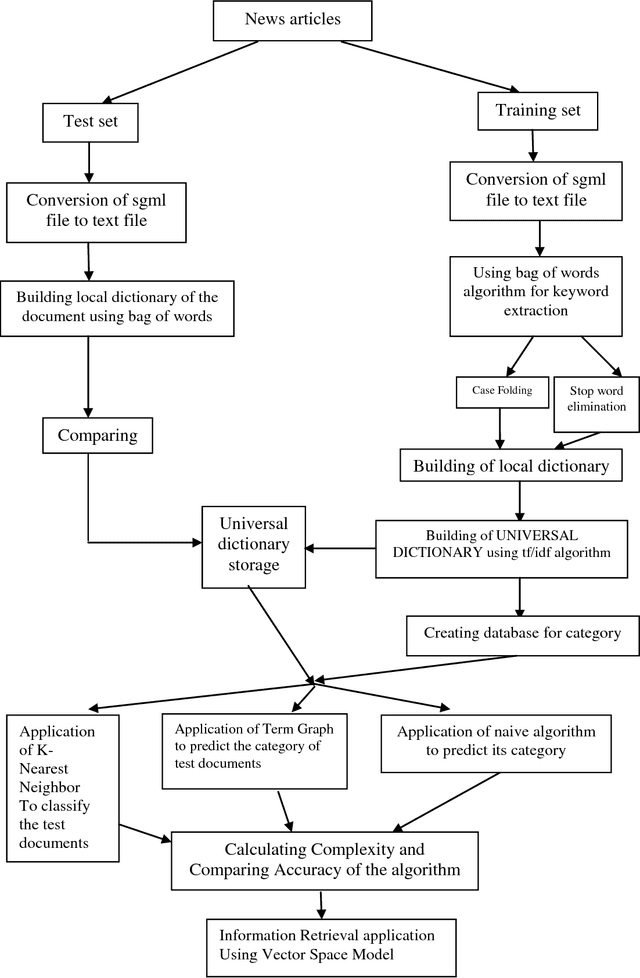
Text Categorization (TC), also known as Text Classification, is the task of automatically classifying a set of text documents into different categories from a predefined set. If a document belongs to exactly one of the categories, it is a single-label classification task; otherwise, it is a multi-label classification task. TC uses several tools from Information Retrieval (IR) and Machine Learning (ML) and has received much attention in the last years from both researchers in the academia and industry developers. In this paper, we first categorize the documents using KNN based machine learning approach and then return the most relevant documents.
* arXiv admin note: text overlap with arXiv:1003.1795, arXiv:1212.2065
by other authors
View paper on