 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Generated Hierarchical Structure of Human Activities to Reveal How Machines Think
Paper and Code
Jan 19, 2021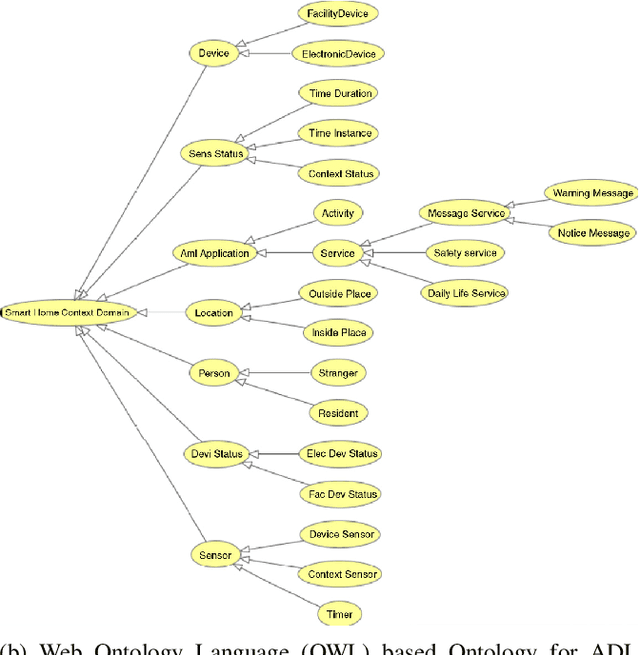
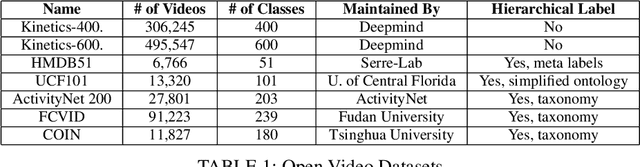
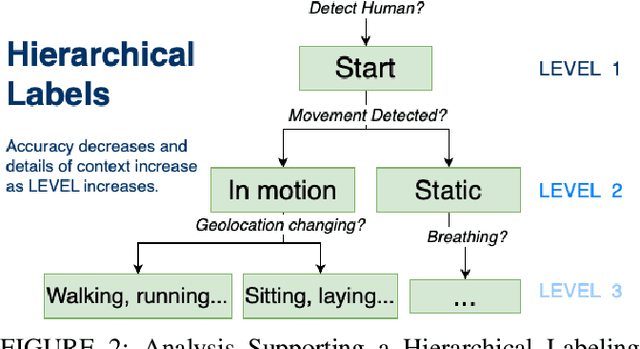
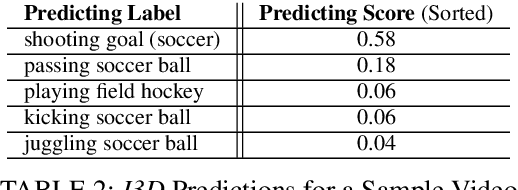
Deep-learning based computer vision models have proved themselves to be ground-breaking approaches to human activity recognition (HAR). However, most existing works are dedicated to improve the prediction accuracy through either creating new model architectures, increasing model complexity, or refining model parameters by training on larger datasets. Here, we propose an alternative idea, differing from existing work, to increase model accuracy and also to shape model predictions to align with human understandings through automatically creating higher-level summarizing labels for similar groups of human activities. First, we argue the importance and feasibility of constructing a hierarchical labeling system for human activity recognition. Then, we utilize the predictions of a black box HAR model to identify similarities between different activities. Finally, we tailor hierarchical clustering methods to automatically generate hierarchical trees of activities and conduct experiments. In this system, the activity labels on the same level will have a designed magnitude of accuracy and reflect a specific amount of activity details. This strategy enables a trade-off between the extent of the details in the recognized activity and the user privacy by masking some sensitive predictions; and also provides possibilities for the use of formerly prohibited invasive models in privacy-concerned scenarios. Since the hierarchy is generated from the machine's perspective, the predictions at the upper levels provide better accuracy, which is especially useful when there are too detailed labels in the training set that are rather trivial to the final prediction goal. Moreover, the analysis of the structure of these trees can reveal the biases in the prediction model and guide future data collection strategies.