Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Comprehension Based on Learning to Rank
Paper and Code
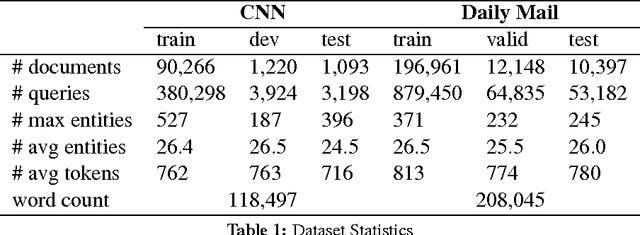
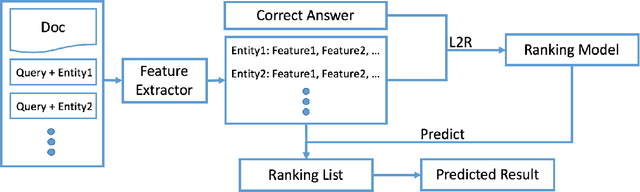


Machine comprehension plays an essential role in NLP and has been widely explored with dataset like MCTest. However, this dataset is too simple and too small for learning true reasoning abilities. \cite{hermann2015teaching} therefore release a large scale news article dataset and propose a deep LSTM reader system for machine comprehension. However, the training process is expensive. We therefore try feature-engineered approach with semantics on the new dataset to see how traditional machine learning technique and semantics can help with machine comprehension. Meanwhile, our proposed L2R reader system achieves good performance with efficiency and less training data.
* 9 pages
View paper on