 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLWA-HAND: Lightweight Attention Hand for Interacting Hand Reconstruction
Paper and Code
Aug 27, 2022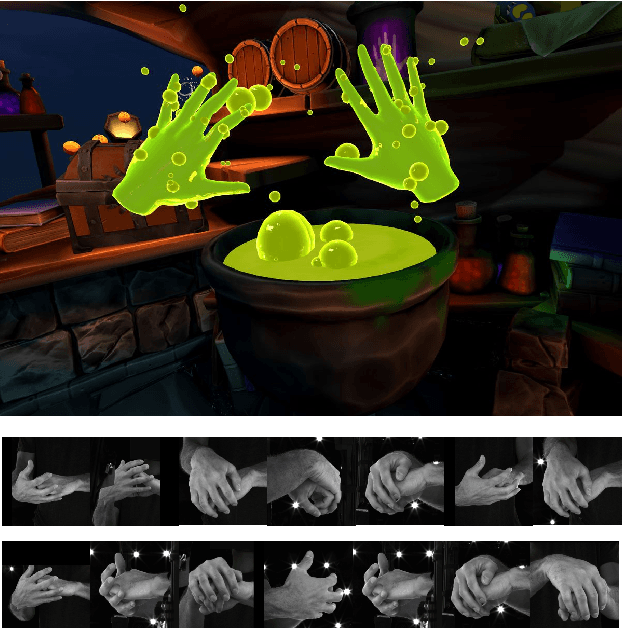

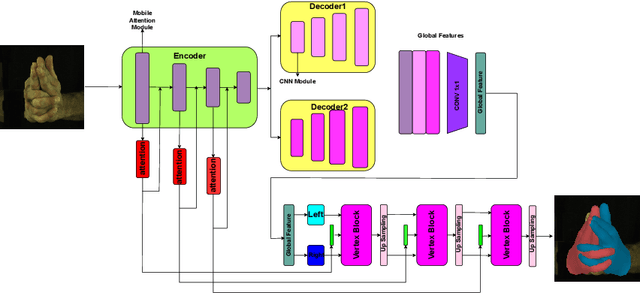

Recent years have witnessed great success for hand reconstruction in real-time applications such as visual reality and augmented reality while interacting with two-hand reconstruction through efficient transformers is left unexplored. In this paper, we propose a method called lightweight attention hand (LWA-HAND) to reconstruct hands in low flops from a single RGB image. To solve the occlusion and interaction problem in efficient attention architectures, we propose three mobile attention modules in this paper. The first module is a lightweight feature attention module that extracts both local occlusion representation and global image patch representation in a coarse-to-fine manner. The second module is a cross image and graph bridge module which fuses image context and hand vertex. The third module is a lightweight cross-attention mechanism that uses element-wise operation for the cross-attention of two hands in linear complexity. The resulting model achieves comparable performance on the InterHand2.6M benchmark in comparison with the state-of-the-art models. Simultaneously, it reduces the flops to $0.47GFlops$ while the state-of-the-art models have heavy computations between $10GFlops$ and $20GFlops$.