 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLupulus: A Flexible Hardware Accelerator for Neural Networks
Paper and Code
May 03, 2020
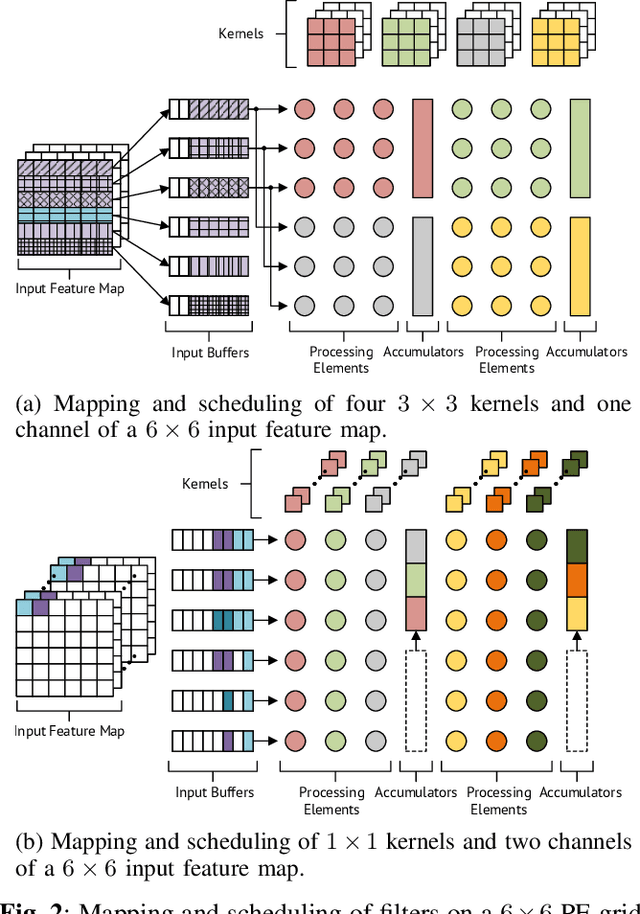
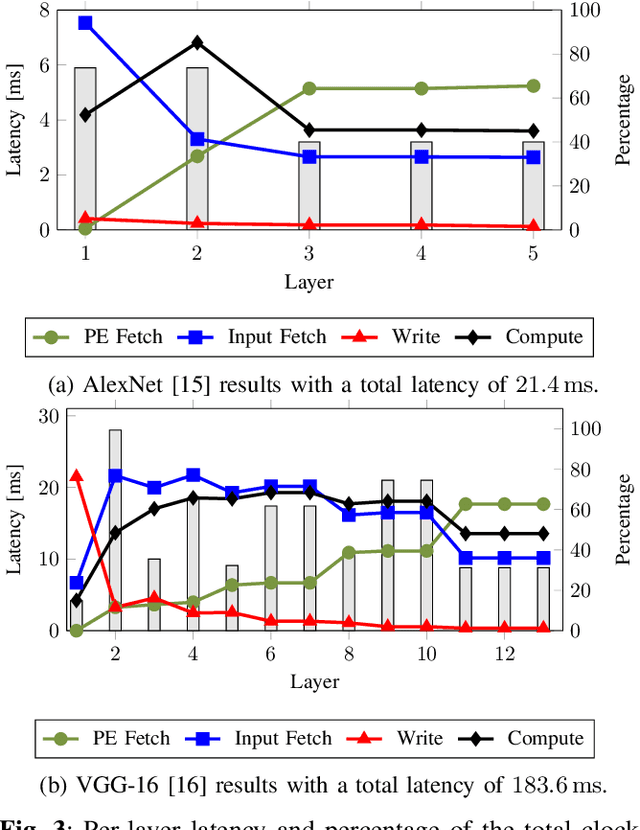
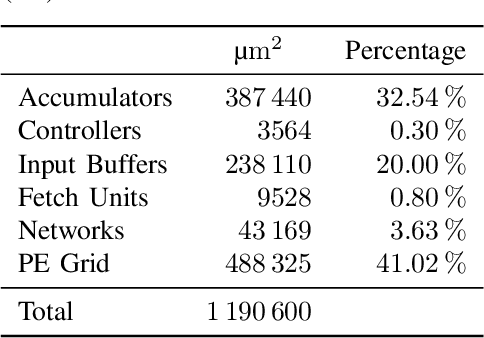
Neural networks have become indispensable for a wide range of applications, but they suffer from high computational- and memory-requirements, requiring optimizations from the algorithmic description of the network to the hardware implementation. Moreover, the high rate of innovation in machine learning makes it important that hardware implementations provide a high level of programmability to support current and future requirements of neural networks. In this work, we present a flexible hardware accelerator for neural networks, called Lupulus, supporting various methods for scheduling and mapping of operations onto the accelerator. Lupulus was implemented in a 28nm FD-SOI technology and demonstrates a peak performance of 380 GOPS/GHz with latencies of 21.4ms and 183.6ms for the convolutional layers of AlexNet and VGG-16, respectively.