Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSOIE: A Large-Scale Dataset for Supervised Open Information Extraction
Paper and Code
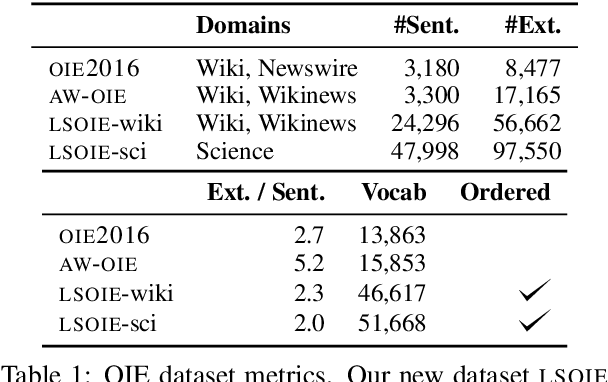
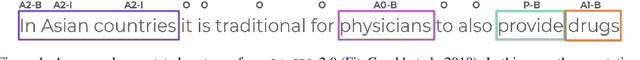
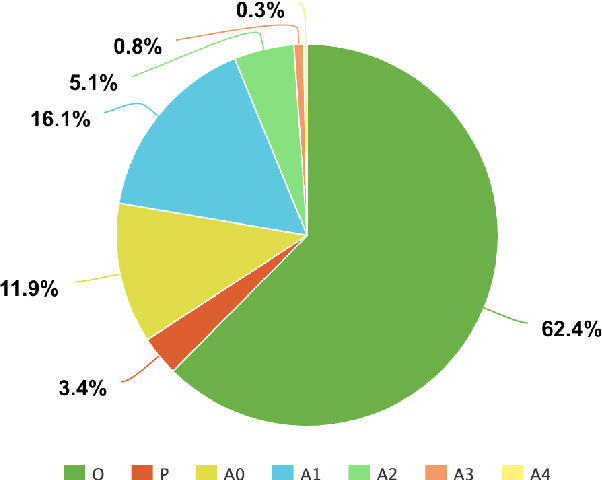

Open Information Extraction (OIE) systems seek to compress the factual propositions of a sentence into a series of n-ary tuples. These tuples are useful for downstream tasks in natural language processing like knowledge base creation, textual entailment, and natural language understanding. However, current OIE datasets are limited in both size and diversity. We introduce a new dataset by converting the QA-SRL 2.0 dataset to a large-scale OIE dataset (LSOIE). Our LSOIE dataset is 20 times larger than the next largest human-annotated OIE dataset. We construct and evaluate several benchmark OIE models on LSOIE, providing baselines for future improvements on the task. Our LSOIE data, models, and code are made publicly available
* EACL 2021
View paper on