 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLScDC-new large scientific dictionary
Paper and Code

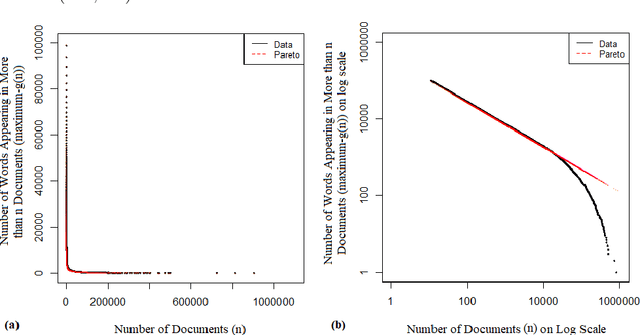


In this paper, we present a scientific corpus of abstracts of academic papers in English -- Leicester Scientific Corpus (LSC). The LSC contains 1,673,824 abstracts of research articles and proceeding papers indexed by Web of Science (WoS) in which publication year is 2014. Each abstract is assigned to at least one of 252 subject categories. Paper metadata include these categories and the number of citations. We then develop scientific dictionaries named Leicester Scientific Dictionary (LScD) and Leicester Scientific Dictionary-Core (LScDC), where words are extracted from the LSC. The LScD is a list of 974,238 unique words (lemmas). The LScDC is a core list (sub-list) of the LScD with 104,223 lemmas. It was created by removing LScD words appearing in not greater than 10 texts in the LSC. LScD and LScDC are available online. Both the corpus and dictionaries are developed to be later used for quantification of meaning in academic texts. Finally, the core list LScDC was analysed by comparing its words and word frequencies with a classic academic word list 'New Academic Word List (NAWL)' containing 963 word families, which is also sampled from an academic corpus. The major sources of the corpus where NAWL is extracted are Cambridge English Corpus (CEC), oral sources and textbooks. We investigate whether two dictionaries are similar in terms of common words and ranking of words. Our comparison leads us to main conclusion: most of words of NAWL (99.6%) are present in the LScDC but two lists differ in word ranking. This difference is measured.