 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRTuner: A Learning Rate Tuner for Deep Neural Networks
Paper and Code
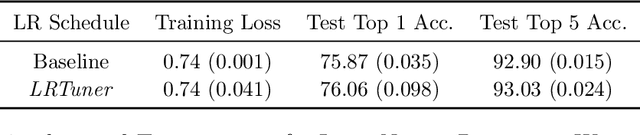
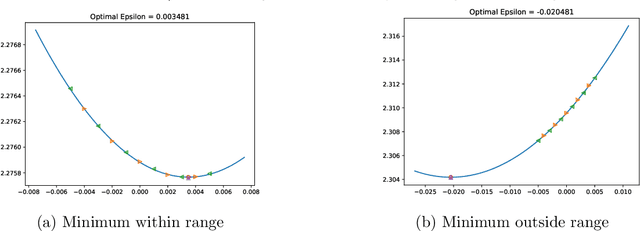

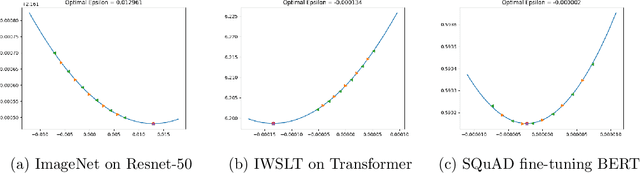
One very important hyperparameter for training deep neural networks is the learning rate schedule of the optimizer. The choice of learning rate schedule determines the computational cost of getting close to a minima, how close you actually get to the minima, and most importantly the kind of local minima (wide/narrow) attained. The kind of minima attained has a significant impact on the generalization accuracy of the network. Current systems employ hand tuned learning rate schedules, which are painstakingly tuned for each network and dataset. Given that the state space of schedules is huge, finding a satisfactory learning rate schedule can be very time consuming. In this paper, we present LRTuner, a method for tuning the learning rate as training proceeds. Our method works with any optimizer, and we demonstrate results on SGD with Momentum, and Adam optimizers. We extensively evaluate LRTuner on multiple datasets, models, and across optimizers. We compare favorably against standard learning rate schedules for the given dataset and models, including ImageNet on Resnet-50, Cifar-10 on Resnet-18, and SQuAD fine-tuning on BERT. For example on ImageNet with Resnet-50, LRTuner shows up to 0.2% absolute gains in test accuracy compared to the hand-tuned baseline schedule. Moreover, LRTuner can achieve the same accuracy as the baseline schedule in 29% less optimization steps.