 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPAT: Learning to Predict Adaptive Threshold for Weakly-supervised Temporal Action Localization
Paper and Code
Oct 25, 2019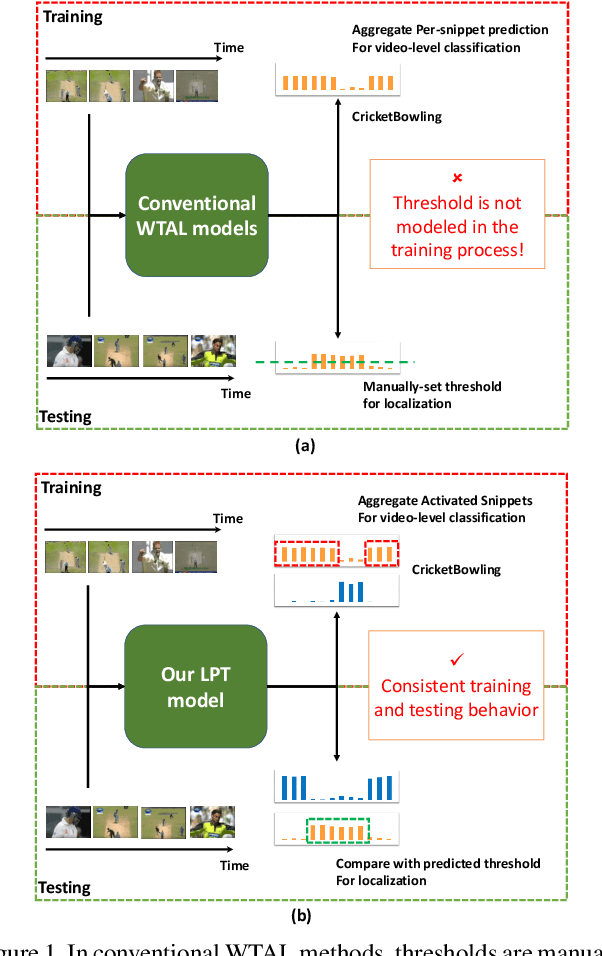
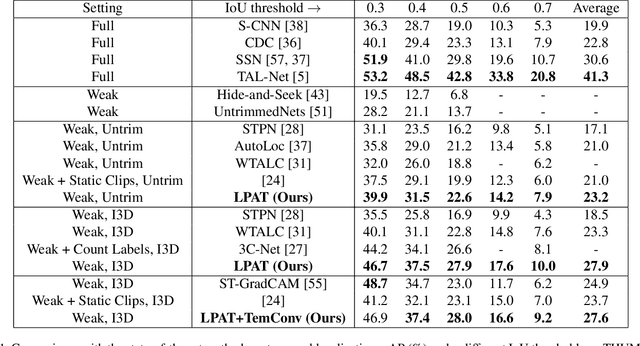
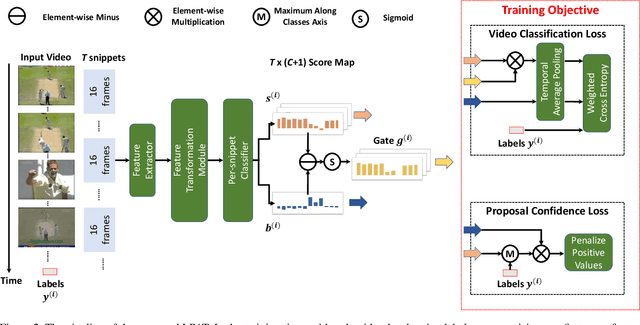

Recently, Weakly-supervised Temporal Action Localization (WTAL) has been densely studied because it can free us from costly annotating temporal boundaries of actions. One prevalent strategy is obtaining action score sequences over time and then truncating segments of scores higher than a fixed threshold at every kept snippet. However, the threshold is not modeled in the training process and manually setting the threshold introduces expert knowledge, which damages the coherence of systems and makes it unfair for comparisons. In this paper, we propose to adaptively set the threshold at each snippet to be its background score, which can be learned to predict (LPAT). In both training and testing time, the predicted threshold is leveraged to localize action segments and the scores of these segments are allocated for video classification. We also identify an important constraint to improve the confidence of generated proposals, and model it as a novel loss term, which facilitates the video classification loss to improve models' localization ability. As such, our LPAT model is able to generate accurate action proposals with only video-level supervision. Extensive experiments on two standard yet challenging datasets, i.e., THUMOS'14 and ActivityNet1.2, show significant improvement over state-of-the-art methods.