 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bound On the Computational Complexity of Discounted Markov Decision Problems
Paper and Code
May 20, 2017
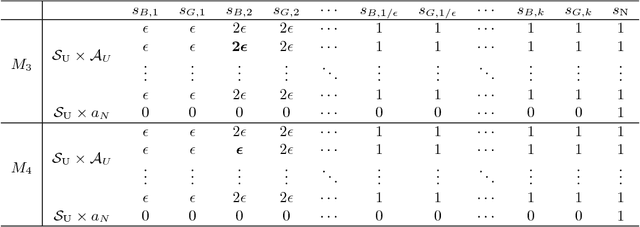

We study the computational complexity of the infinite-horizon discounted-reward Markov Decision Problem (MDP) with a finite state space $|\mathcal{S}|$ and a finite action space $|\mathcal{A}|$. We show that any randomized algorithm needs a running time at least $\Omega(|\mathcal{S}|^2|\mathcal{A}|)$ to compute an $\epsilon$-optimal policy with high probability. We consider two variants of the MDP where the input is given in specific data structures, including arrays of cumulative probabilities and binary trees of transition probabilities. For these cases, we show that the complexity lower bound reduces to $\Omega\left( \frac{|\mathcal{S}| |\mathcal{A}|}{\epsilon} \right)$. These results reveal a surprising observation that the computational complexity of the MDP depends on the data structure of input.