Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Neural Headline Generation
Paper and Code
Jul 31, 2017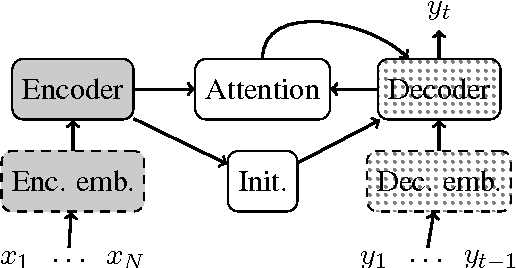
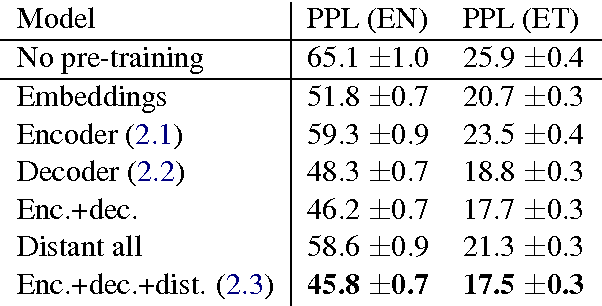
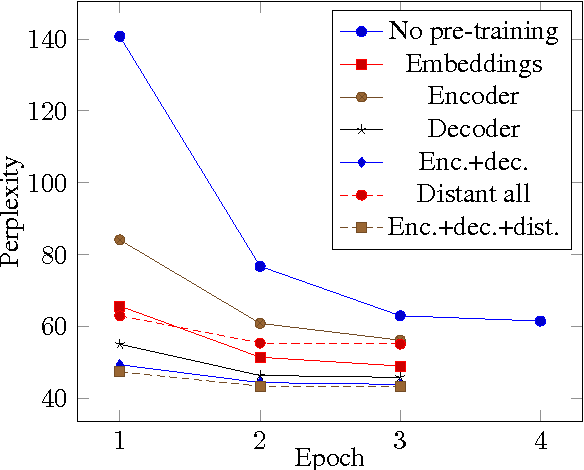
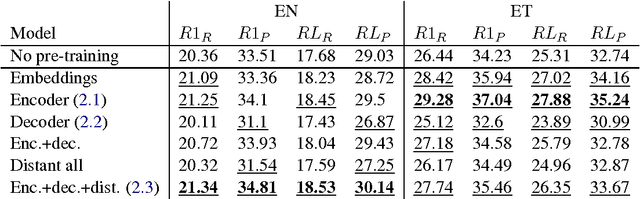
Recent neural headline generation models have shown great results, but are generally trained on very large datasets. We focus our efforts on improving headline quality on smaller datasets by the means of pretraining. We propose new methods that enable pre-training all the parameters of the model and utilize all available text, resulting in improvements by up to 32.4% relative in perplexity and 2.84 points in ROUGE.
* Accepted to EMNLP 2017 Workshop on New Frontiers in Summarization
View paper on