 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-resource bilingual lexicon extraction using graph based word embeddings
Paper and Code
Oct 06, 2017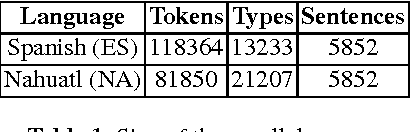
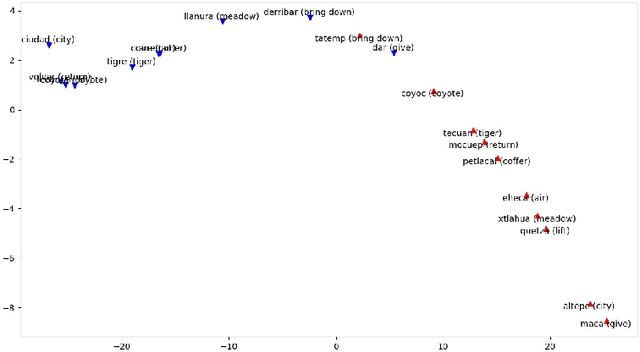

In this work we focus on the task of automatically extracting bilingual lexicon for the language pair Spanish-Nahuatl. This is a low-resource setting where only a small amount of parallel corpus is available. Most of the downstream methods do not work well under low-resources conditions. This is specially true for the approaches that use vectorial representations like Word2Vec. Our proposal is to construct bilingual word vectors from a graph. This graph is generated using translation pairs obtained from an unsupervised word alignment method. We show that, in a low-resource setting, these type of vectors are successful in representing words in a bilingual semantic space. Moreover, when a linear transformation is applied to translate words from one language to another, our graph based representations considerably outperform the popular setting that uses Word2Vec.