 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Mirror-Prox for Nonsmooth and Low-Rank Matrix Optimization Problems
Paper and Code
Jun 23, 2022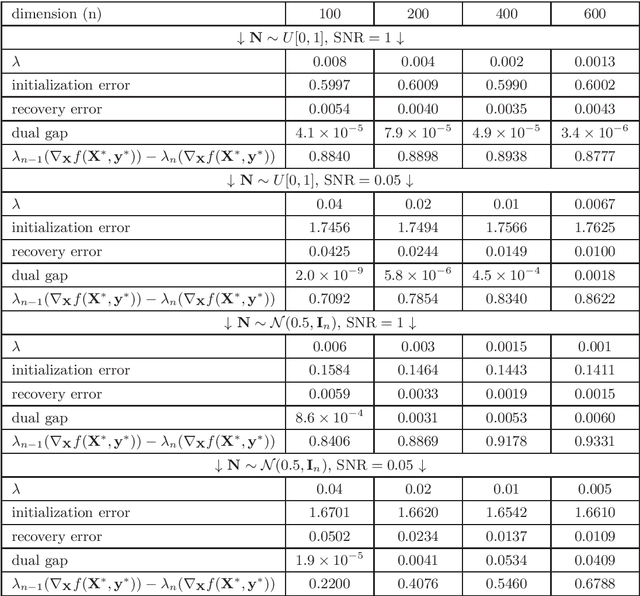
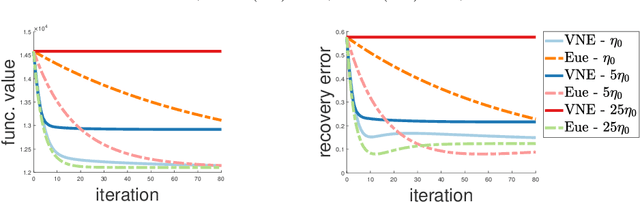
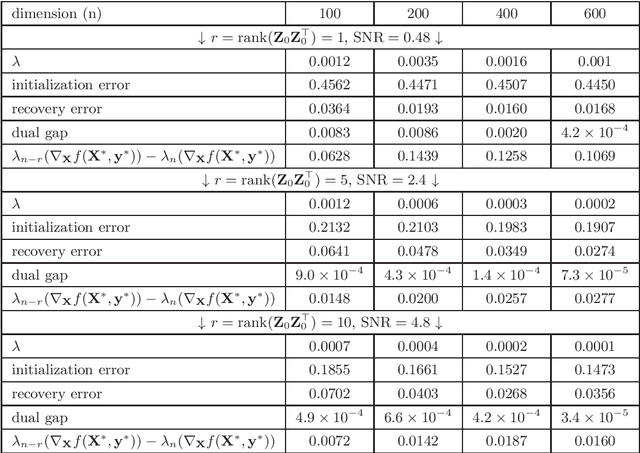
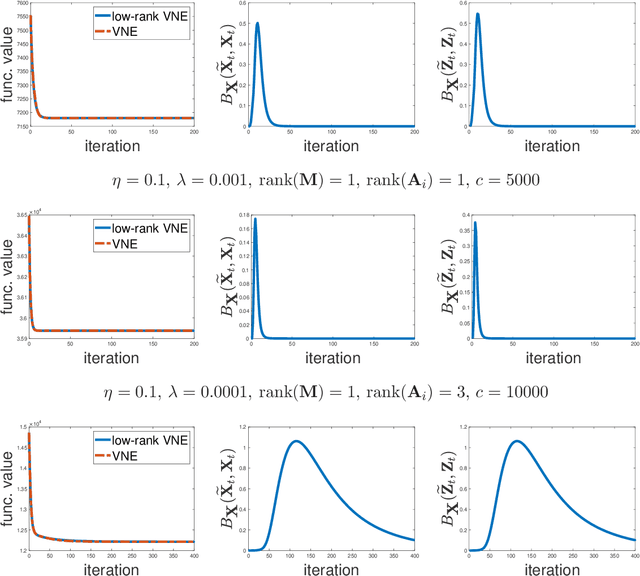
Low-rank and nonsmooth matrix optimization problems capture many fundamental tasks in statistics and machine learning. While significant progress has been made in recent years in developing efficient methods for \textit{smooth} low-rank optimization problems that avoid maintaining high-rank matrices and computing expensive high-rank SVDs, advances for nonsmooth problems have been slow paced. In this paper we consider standard convex relaxations for such problems. Mainly, we prove that under a \textit{strict complementarity} condition and under the relatively mild assumption that the nonsmooth objective can be written as a maximum of smooth functions, approximated variants of two popular \textit{mirror-prox} methods: the Euclidean \textit{extragradient method} and mirror-prox with \textit{matrix exponentiated gradient updates}, when initialized with a "warm-start", converge to an optimal solution with rate $O(1/t)$, while requiring only two \textit{low-rank} SVDs per iteration. Moreover, for the extragradient method we also consider relaxed versions of strict complementarity which yield a trade-off between the rank of the SVDs required and the radius of the ball in which we need to initialize the method. We support our theoretical results with empirical experiments on several nonsmooth low-rank matrix recovery tasks, demonstrating both the plausibility of the strict complementarity assumption, and the efficient convergence of our proposed low-rank mirror-prox variants.