 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Memory End-to-End Training for Iterative Joint Speech Dereverberation and Separation with A Neural Source Model
Paper and Code
Oct 13, 2021

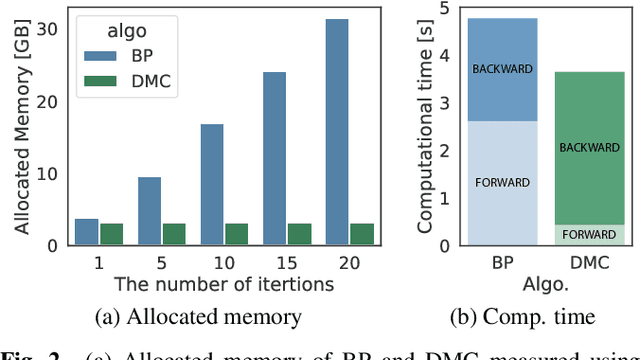

We propose an end-to-end framework for training iterative multi-channel joint dereverberation and source separation with a neural source model. We combine the unified dereverberation and separation update equations of ILRMA-T with a deep neural network (DNN) serving as source model. The weights of the model are directly trained by gradient descent with a permutation invariant loss on the output time-domain signals. One drawback of this approach is that backpropagation consumes memory linearly in the number of iterations. This severely limits the number of iterations, channels, or signal lengths that can be used during training. We introduce demixing matrix checkpointing to bypass this problem, a new technique that reduces the total memory cost to that of a single iteration. In experiments, we demonstrate that the introduced framework results in high-performance in terms of conventional speech quality metrics and word error rate. Furthermore, it generalizes to number of channels unseen during training.