 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-dimensional Interpretable Kernels with Conic Discriminant Functions for Classification
Paper and Code
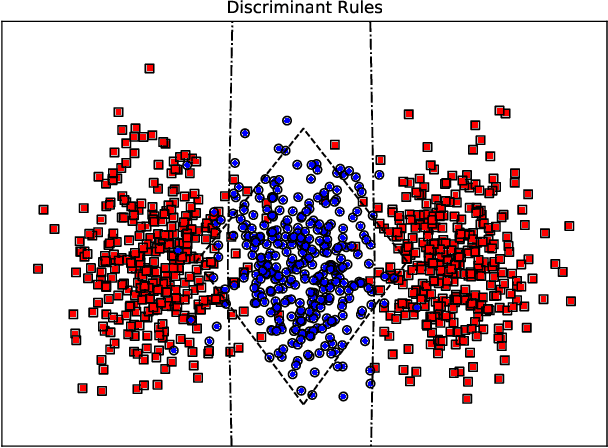
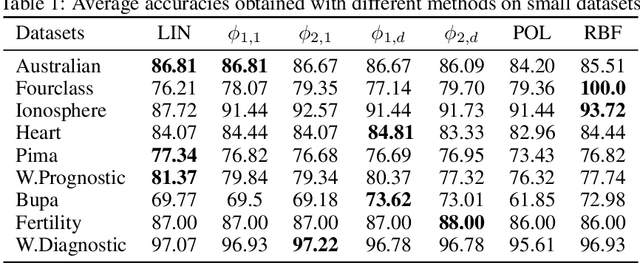
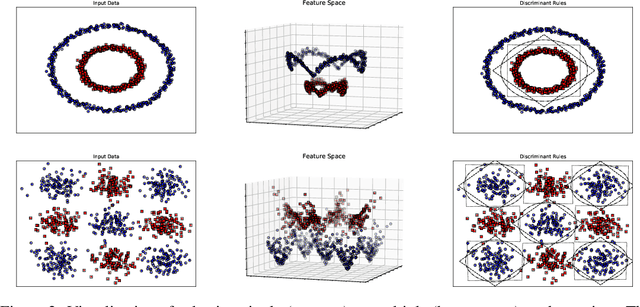
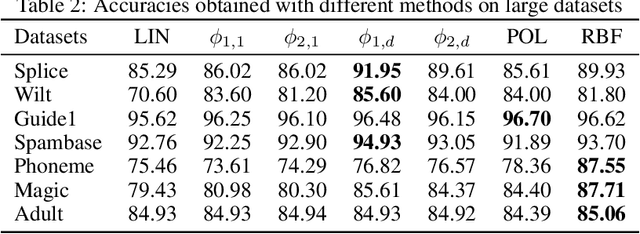
Kernels are often developed and used as implicit mapping functions that show impressive predictive power due to their high-dimensional feature space representations. In this study, we gradually construct a series of simple feature maps that lead to a collection of interpretable low-dimensional kernels. At each step, we keep the original features and make sure that the increase in the dimension of input data is extremely low, so that the resulting discriminant functions remain interpretable and amenable to fast training. Despite our persistence on interpretability, we obtain high accuracy results even without in-depth hyperparameter tuning. Comparison of our results against several well-known kernels on benchmark datasets show that the proposed kernels are competitive in terms of prediction accuracy, while the training times are significantly lower than those obtained with state-of-the-art kernel implementations.