 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image
Paper and Code


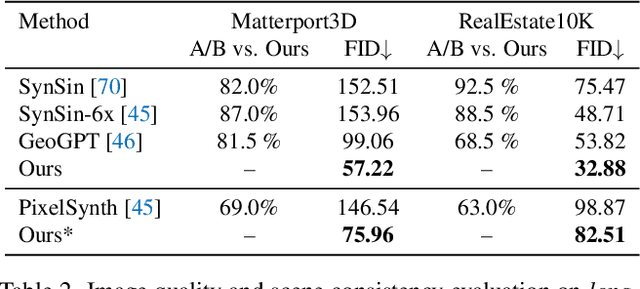

Novel view synthesis from a single image has recently attracted a lot of attention, and it has been primarily advanced by 3D deep learning and rendering techniques. However, most work is still limited by synthesizing new views within relatively small camera motions. In this paper, we propose a novel approach to synthesize a consistent long-term video given a single scene image and a trajectory of large camera motions. Our approach utilizes an autoregressive Transformer to perform sequential modeling of multiple frames, which reasons the relations between multiple frames and the corresponding cameras to predict the next frame. To facilitate learning and ensure consistency among generated frames, we introduce a locality constraint based on the input cameras to guide self-attention among a large number of patches across space and time. Our method outperforms state-of-the-art view synthesis approaches by a large margin, especially when synthesizing long-term future in indoor 3D scenes. Project page at https://xrenaa.github.io/look-outside-room/.