 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Data Sharing under Exclusivity Attacks
Paper and Code

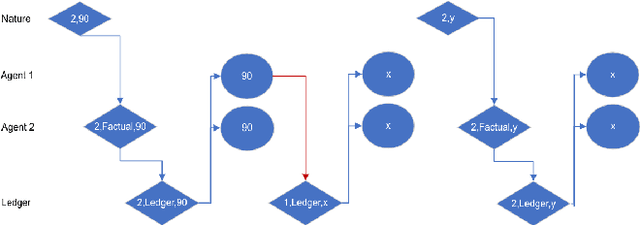


The quality of learning generally improves with the scale and diversity of data. Companies and institutions can therefore benefit from building models over shared data. Many cloud and blockchain platforms, as well as government initiatives, are interested in providing this type of service. These cooperative efforts face a challenge, which we call ``exclusivity attacks''. A firm can share distorted data, so that it learns the best model fit, but is also able to mislead others. We study protocols for long-term interactions and their vulnerability to these attacks, in particular for regression and clustering tasks. We conclude that the choice of protocol, as well as the number of Sybil identities an attacker may control, is material to vulnerability.