 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Sequence Modeling with Attention Tensorization: From Sequence to Tensor Learning
Paper and Code

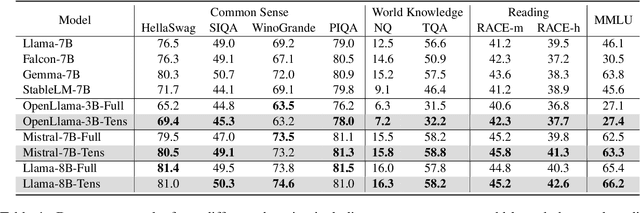

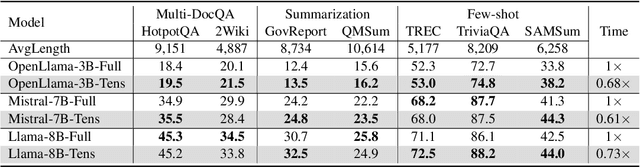
As the demand for processing extended textual data grows, the ability to handle long-range dependencies and maintain computational efficiency is more critical than ever. One of the key issues for long-sequence modeling using attention-based model is the mismatch between the limited-range modeling power of full attention and the long-range token dependency in the input sequence. In this work, we propose to scale up the attention receptive field by tensorizing long input sequences into compact tensor representations followed by attention on each transformed dimension. The resulting Tensorized Attention can be adopted as efficient transformer backbones to extend input context length with improved memory and time efficiency. We show that the proposed attention tensorization encodes token dependencies as a multi-hop attention process, and is equivalent to Kronecker decomposition of full attention. Extensive experiments show that tensorized attention can be used to adapt pretrained LLMs with improved efficiency. Notably, Llama-8B with tensorization is trained under 32,768 context length and can steadily extrapolate to 128k length during inference with $11\times$ speedup, compared to full attention with FlashAttention-2.