 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Sensitive Image Retrieval and Tagging
Paper and Code
Jul 07, 2020
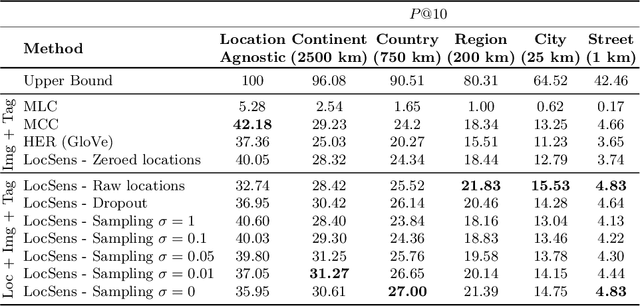

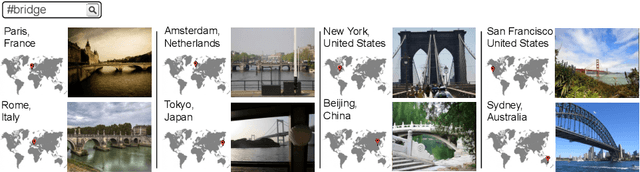
People from different parts of the globe describe objects and concepts in distinct manners. Visual appearance can thus vary across different geographic locations, which makes location a relevant contextual information when analysing visual data. In this work, we address the task of image retrieval related to a given tag conditioned on a certain location on Earth. We present LocSens, a model that learns to rank triplets of images, tags and coordinates by plausibility, and two training strategies to balance the location influence in the final ranking. LocSens learns to fuse textual and location information of multimodal queries to retrieve related images at different levels of location granularity, and successfully utilizes location information to improve image tagging.