 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization, Convexity, and Star Aggregation
Paper and Code
May 19, 2021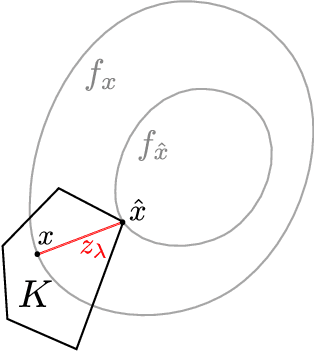
Offset Rademacher complexities have been shown to imply sharp, data-dependent upper bounds for the square loss in a broad class of problems including improper statistical learning and online learning. We show that in the statistical setting, the offset complexity upper bound can be generalized to any loss satisfying a certain uniform convexity condition. Amazingly, this condition is shown to also capture exponential concavity and self-concordance, uniting several apparently disparate results. By a unified geometric argument, these bounds translate directly to improper learning in a non-convex class using Audibert's "star algorithm." As applications, we recover the optimal rates for proper and improper learning with the $p$-loss, $1 < p < \infty$, closing the gap for $p > 2$, and show that improper variants of empirical risk minimization can attain fast rates for logistic regression and other generalized linear models.