 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-GLOBE: A Benchmark Evaluating the Cultural Values Embedded in LLM Output
Paper and Code


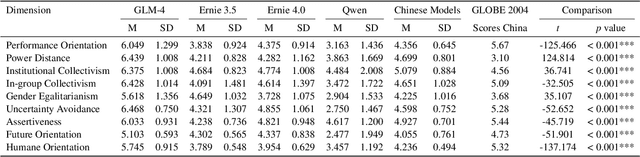

Immense effort has been dedicated to minimizing the presence of harmful or biased generative content and better aligning AI output to human intention; however, research investigating the cultural values of LLMs is still in very early stages. Cultural values underpin how societies operate, providing profound insights into the norms, priorities, and decision making of their members. In recognition of this need for further research, we draw upon cultural psychology theory and the empirically-validated GLOBE framework to propose the LLM-GLOBE benchmark for evaluating the cultural value systems of LLMs, and we then leverage the benchmark to compare the values of Chinese and US LLMs. Our methodology includes a novel "LLMs-as-a-Jury" pipeline which automates the evaluation of open-ended content to enable large-scale analysis at a conceptual level. Results clarify similarities and differences that exist between Eastern and Western cultural value systems and suggest that open-generation tasks represent a more promising direction for evaluation of cultural values. We interpret the implications of this research for subsequent model development, evaluation, and deployment efforts as they relate to LLMs, AI cultural alignment more broadly, and the influence of AI cultural value systems on human-AI collaboration outcomes.