 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiT: Zero-Shot Transfer with Locked-image Text Tuning
Paper and Code
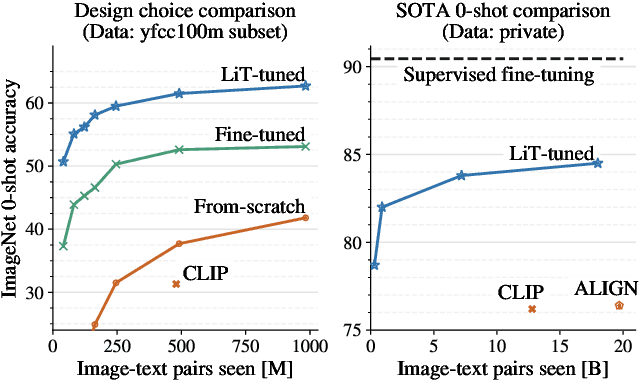
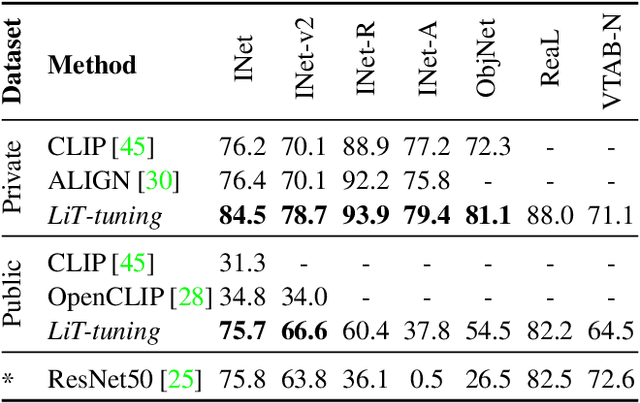
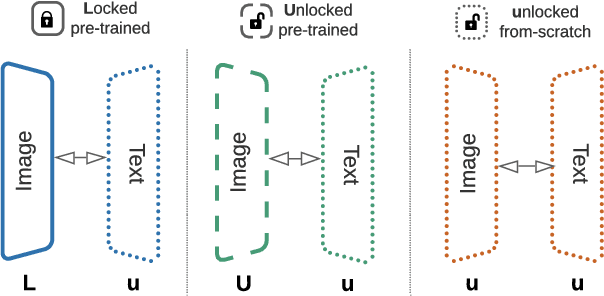

This paper presents contrastive-tuning, a simple method employing contrastive training to align image and text models while still taking advantage of their pre-training. In our empirical study we find that locked pre-trained image models with unlocked text models work best. We call this instance of contrastive-tuning "Locked-image Text tuning" (LiT-tuning), which just teaches a text model to read out good representations from a pre-trained image model for new tasks. A LiT-tuned model gains the capability of zero-shot transfer to new vision tasks, such as image classification or retrieval. The proposed LiT-tuning is widely applicable; it works reliably with multiple pre-training methods (supervised and unsupervised) and across diverse architectures (ResNet, Vision Transformers and MLP-Mixer) using three different image-text datasets. With the transformer-based pre-trained ViT-g/14 model, the LiT-tuned model achieves 84.5% zero-shot transfer accuracy on the ImageNet test set, and 81.1% on the challenging out-of-distribution ObjectNet test set.