 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLISPR: An Options Framework for Policy Reuse with Reinforcement Learning
Paper and Code
Dec 29, 2020
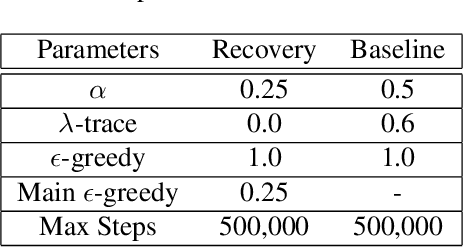
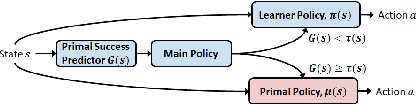

We propose a framework for transferring any existing policy from a potentially unknown source MDP to a target MDP. This framework (1) enables reuse in the target domain of any form of source policy, including classical controllers, heuristic policies, or deep neural network-based policies, (2) attains optimality under suitable theoretical conditions, and (3) guarantees improvement over the source policy in the target MDP. These are achieved by packaging the source policy as a black-box option in the target MDP and providing a theoretically grounded way to learn the option's initiation set through general value functions. Our approach facilitates the learning of new policies by (1) maximizing the target MDP reward with the help of the black-box option, and (2) returning the agent to states in the learned initiation set of the black-box option where it is already optimal. We show that these two variants are equivalent in performance under some conditions. Through a series of experiments in simulated environments, we demonstrate that our framework performs excellently in sparse reward problems given (sub-)optimal source policies and improves upon prior art in transfer methods such as continual learning and progressive networks, which lack our framework's desirable theoretical properties.