 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipschitz regularized Deep Neural Networks converge and generalize
Paper and Code
Oct 03, 2018

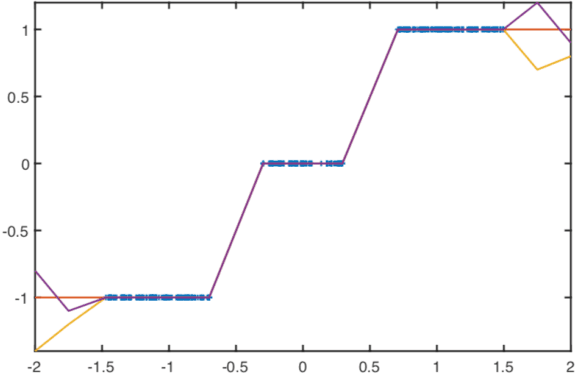

Generalization of deep neural networks (DNNs) is an open problem which, if solved, could impact the reliability and verification of deep neural network architectures. In this paper, we show that if the usual fidelity term used in training DNNs is augmented by a Lipschitz regularization term, then the networks converge and generalize. The convergence is in the limit as the number of data points, $n\to \infty$, while also allowing the network to grow as needed to fit the data. Two regimes are identified: in the case of clean labels, we prove convergence to the label function which corresponds to zero loss, in the case of corrupted labels which we prove convergence to a regularized label function which is the solution of a limiting variational problem. In both cases, a convergence rate is also provided.