 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking average- and worst-case perturbation robustness via class selectivity and dimensionality
Paper and Code
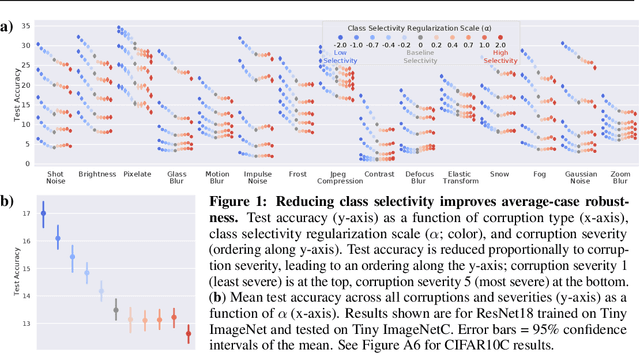
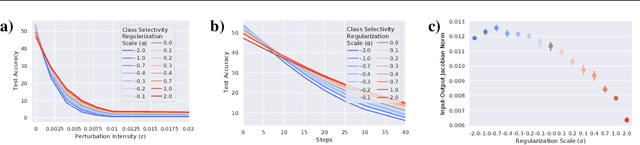
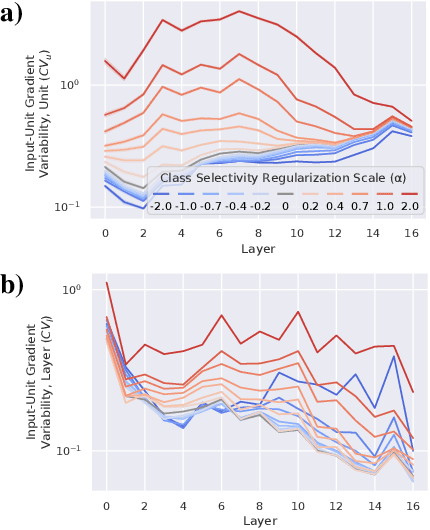
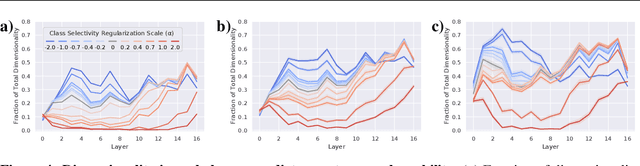
Representational sparsity is known to affect robustness to input perturbations in deep neural networks (DNNs), but less is known about how the semantic content of representations affects robustness. Class selectivity-the variability of a unit's responses across data classes or dimensions-is one way of quantifying the sparsity of semantic representations. Given recent evidence that class selectivity may not be necessary for, and can even impair generalization, we investigated whether it also confers robustness (or vulnerability) to perturbations of input data. We found that class selectivity leads to increased vulnerability to average-case (naturalistic) perturbations in ResNet18 and ResNet20, as measured using Tiny ImageNetC and CIFAR10C, respectively. Networks regularized to have lower levels of class selectivity are more robust to average-case perturbations, while networks with higher class selectivity are more vulnerable. In contrast, we found that class selectivity increases robustness to worst-case (i.e. white box adversarial) perturbations, suggesting that while decreasing class selectivity is helpful for average-case robustness, it is harmful for worst-case robustness. To explain this difference, we studied the dimensionality of the networks' representations: we found that the dimensionality of early-layer representations is inversely proportional to a network's class selectivity, and that adversarial samples cause a larger increase in early-layer dimensionality than corrupted samples. We also found that the input-unit gradient was more variable across samples and units in high-selectivity networks compared to low-selectivity networks. These results lead to the conclusion that units participate more consistently in low-selectivity regimes compared to high-selectivity regimes, effectively creating a larger attack surface and hence vulnerability to worst-case perturbations.