 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistically Grounded Analysis of Language Models using Shapley Head Values
Paper and Code
Oct 17, 2024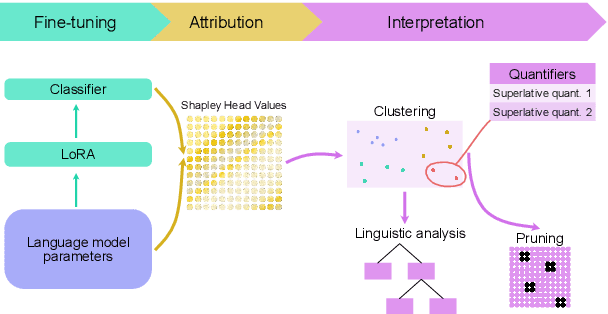



Understanding how linguistic knowledge is encoded in language models is crucial for improving their generalisation capabilities. In this paper, we investigate the processing of morphosyntactic phenomena, by leveraging a recently proposed method for probing language models via Shapley Head Values (SHVs). Using the English language BLiMP dataset, we test our approach on two widely used models, BERT and RoBERTa, and compare how linguistic constructions such as anaphor agreement and filler-gap dependencies are handled. Through quantitative pruning and qualitative clustering analysis, we demonstrate that attention heads responsible for processing related linguistic phenomena cluster together. Our results show that SHV-based attributions reveal distinct patterns across both models, providing insights into how language models organize and process linguistic information. These findings support the hypothesis that language models learn subnetworks corresponding to linguistic theory, with potential implications for cross-linguistic model analysis and interpretability in Natural Language Processing (NLP).