 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic data mining with complex networks: a stylometric-oriented approach
Paper and Code
Aug 16, 2018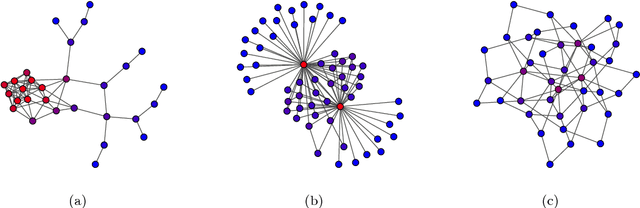
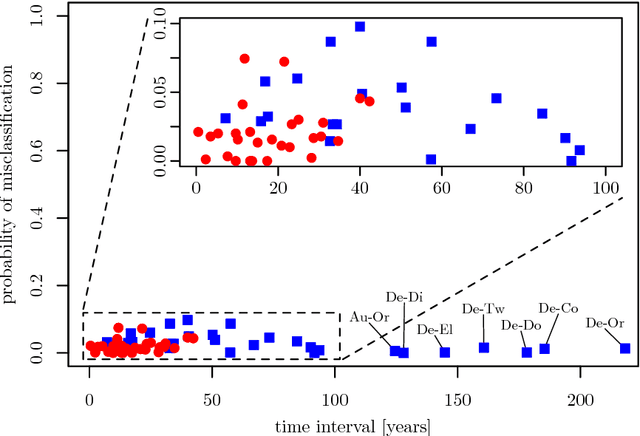
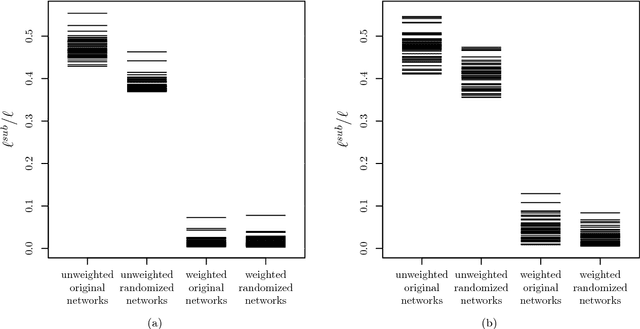
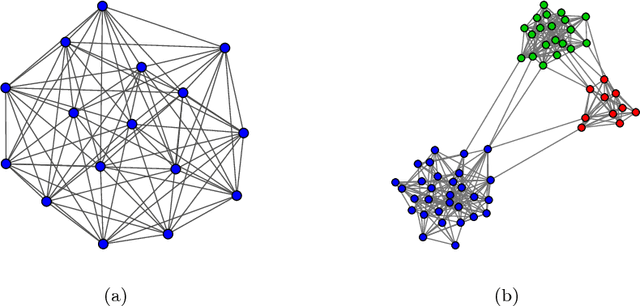
By representing a text by a set of words and their co-occurrences, one obtains a word-adjacency network - a network being in a way a reduced representation of the given language sample. In this paper, the possibility of using network representation in order to extract information about individual language styles of literary texts is studied. By determining selected quantitative characteristics of the networks and applying machine learning algorithms, it is made possible to distinguish between texts of different authors. It turns out that within the studied set of texts in English and Polish, the properly rescaled weighted clustering coefficients and weighted degrees of only a few nodes in the word-adjacency networks are sufficient to obtain the accuracy of authorship attribution over 90\%. A correspondence between the authorship of texts and the structure of word-adjacency networks can therefore clearly be found; it may be stated that the network representation allows to distinguish individual language styles by comparing the way the authors use particular words and punctuation marks. The presented approach can be viewed as a generalization of the authorship attribution methods based on simplest lexical features. Apart from the characteristics given above, other network parameters are studied, both local and global ones, for both the unweighted and weighted networks. Their potential to capture the diversity of writing styles is discussed; some differences between languages are also observed.