Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear time dynamic programming for the exact path of optimal models selected from a finite set
Paper and Code



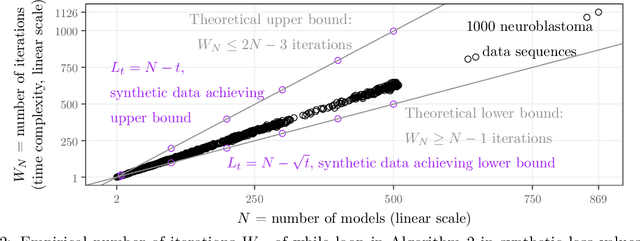
Many learning algorithms are formulated in terms of finding model parameters which minimize a data-fitting loss function plus a regularizer. When the regularizer involves the l0 pseudo-norm, the resulting regularization path consists of a finite set of models. The fastest existing algorithm for computing the breakpoints in the regularization path is quadratic in the number of models, so it scales poorly to high dimensional problems. We provide new formal proofs that a dynamic programming algorithm can be used to compute the breakpoints in linear time. Empirical results on changepoint detection problems demonstrate the improved accuracy and speed relative to grid search and the previous quadratic time algorithm.
* 14 pages
View paper on