 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-memory and Decomposition-invariant Linearly Convergent Conditional Gradient Algorithm for Structured Polytopes
Paper and Code
May 20, 2016
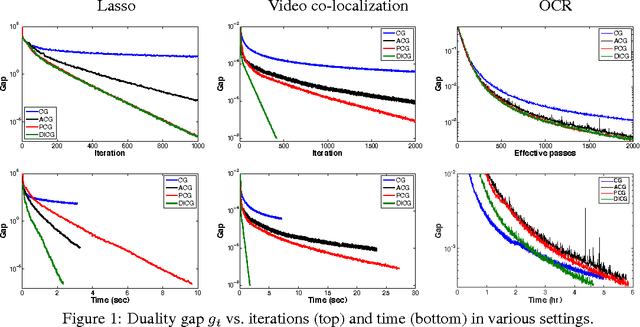
Recently, several works have shown that natural modifications of the classical conditional gradient method (aka Frank-Wolfe algorithm) for constrained convex optimization, provably converge with a linear rate when: i) the feasible set is a polytope, and ii) the objective is smooth and strongly-convex. However, all of these results suffer from two significant shortcomings: large memory requirement due to the need to store an explicit convex decomposition of the current iterate, and as a consequence, large running-time overhead per iteration, and worst case convergence rate that depends unfavorably on the dimension. In this work we present a new conditional gradient variant and a corresponding analysis that improves on both of the above shortcomings. In particular: both memory and computation overheads are only linear in the dimension. Moreover, in case the optimal solution is sparse, the new convergence rate replaces a factor which is at least linear in the dimension in previous works, with a linear dependence on the number of non-zeros in the optimal solution. At the heart of our method, and corresponding analysis, is a novel way to compute decomposition-invariant away-steps. While our theoretical guarantees do not apply to any polytope, they apply to several important structured polytopes that capture central concepts such as paths in graphs, perfect matchings in bipartite graphs, marginal distributions that arise in structured prediction tasks, and more. Our theoretical findings are complemented by empirical evidence which shows that our method delivers state-of-the-art performance.