 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of Approximating the Median Treatment Effect
Paper and Code
Mar 15, 2024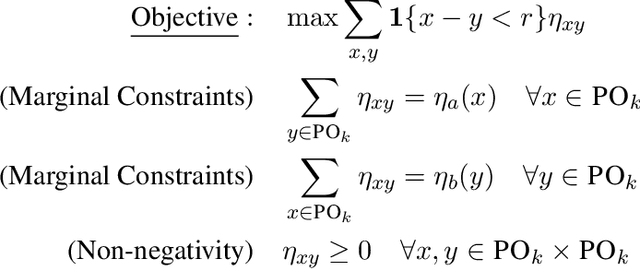

Average Treatment Effect (ATE) estimation is a well-studied problem in causal inference. However, it does not necessarily capture the heterogeneity in the data, and several approaches have been proposed to tackle the issue, including estimating the Quantile Treatment Effects. In the finite population setting containing $n$ individuals, with treatment and control values denoted by the potential outcome vectors $\mathbf{a}, \mathbf{b}$, much of the prior work focused on estimating median$(\mathbf{a}) -$ median$(\mathbf{b})$, where median($\mathbf x$) denotes the median value in the sorted ordering of all the values in vector $\mathbf x$. It is known that estimating the difference of medians is easier than the desired estimand of median$(\mathbf{a-b})$, called the Median Treatment Effect (MTE). The fundamental problem of causal inference -- for every individual $i$, we can only observe one of the potential outcome values, i.e., either the value $a_i$ or $b_i$, but not both, makes estimating MTE particularly challenging. In this work, we argue that MTE is not estimable and detail a novel notion of approximation that relies on the sorted order of the values in $\mathbf{a-b}$. Next, we identify a quantity called variability that exactly captures the complexity of MTE estimation. By drawing connections to instance-optimality studied in theoretical computer science, we show that every algorithm for estimating the MTE obtains an approximation error that is no better than the error of an algorithm that computes variability. Finally, we provide a simple linear time algorithm for computing the variability exactly. Unlike much prior work, a particular highlight of our work is that we make no assumptions about how the potential outcome vectors are generated or how they are correlated, except that the potential outcome values are $k$-ary, i.e., take one of $k$ discrete values.