 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexiconNet: An End-to-End Handwritten Paragraph Text Recognition System
Paper and Code
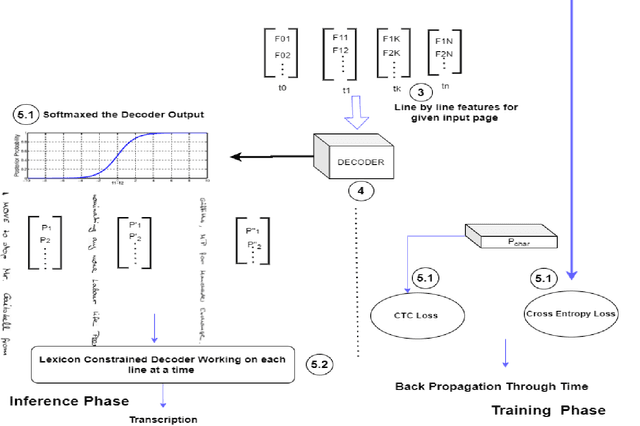
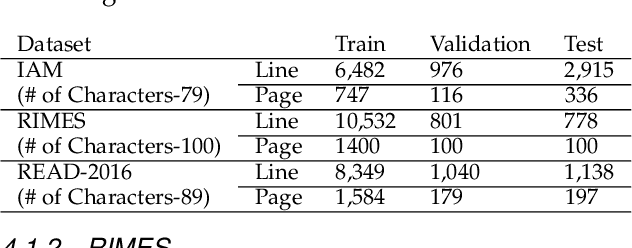
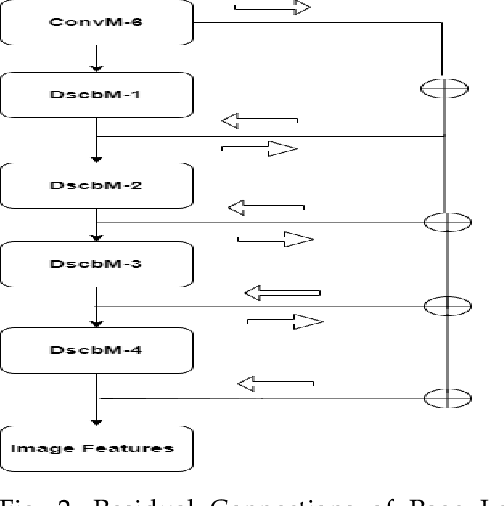
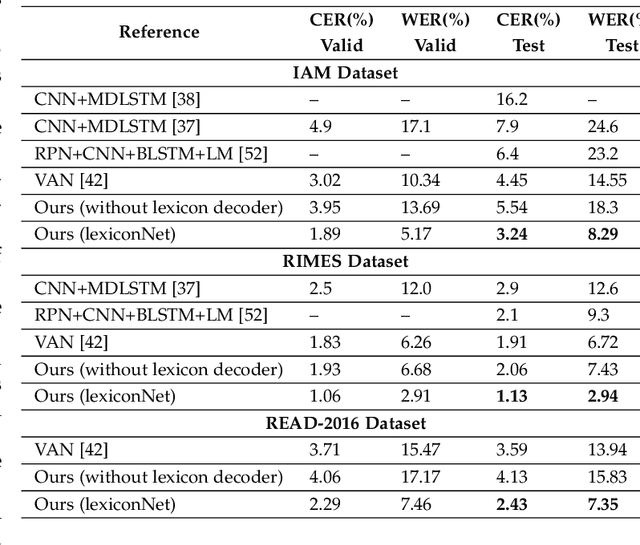
Historical documents present in the form of libraries needs to be digitised. The recognition of these unconstrained cursive handwritten documents is a challenging task. In the present work, neural network based classifier is used. The recognition of scanned document images which are easy to train on neural network based systems is usually done by a two step approach: segmentation followed by recognition. This approach has several shortcomings, which includes identification of text regions, layout diversity analysis present within pages and ground truth segmentation. These processes are prone to errors that create bottleneck in the recognition accuracies. Thus in this study, an end-to-end paragraph recognition system is presented with internal line segmentation and lexicon decoder as post processing step, which is free from those errors. We named our model as LexiconNet. In LexiconNet, given a paragraph image a combination of convolution and depth-wise separable convolutional modules generates the two dimension feature map of the image. The attention module is responsible for internal line segmentation that consequently processing a page in a line by line manner. At decoding step, we have added connectionist temporal classification based word beam search decoder as a post processing step. Our approach reports state-of-the-art results on standard datasets. The reported character error rate is 3.24% on IAM dataset with 27.19% improvement, 1.13% on RIMES with 40.83% improvement and 2.43% on READ-16 dataset with 32.31% improvement from existing literature and the word error rate is 8.29% on IAM dataset with 43.02% improvement, 2.94% on RIMES dataset with 56.25% improvement and 7.35% on READ-2016 dataset with 47.27% improvement from the existing results. The character error rate and word error rate reported in this work surpasses the results reported in literature.