 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicon-based Methods vs. BERT for Text Sentiment Analysis
Paper and Code
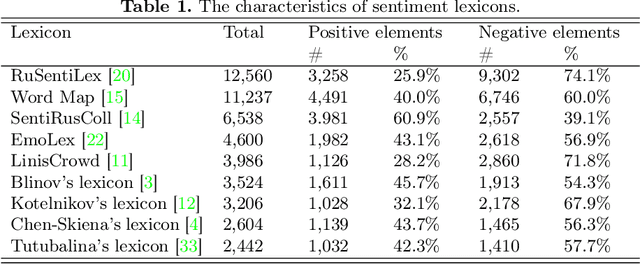

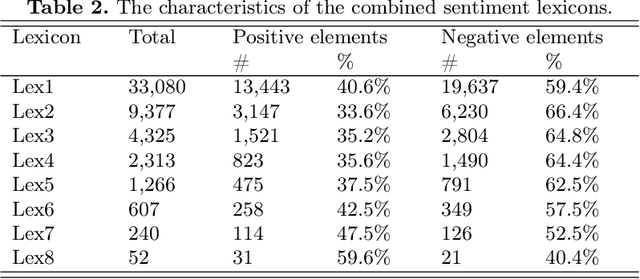
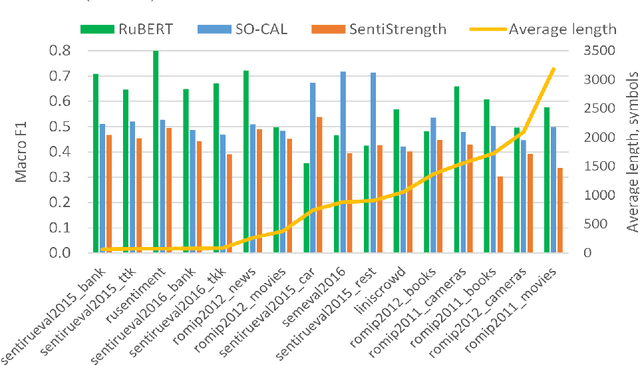
The performance of sentiment analysis methods has greatly increased in recent years. This is due to the use of various models based on the Transformer architecture, in particular BERT. However, deep neural network models are difficult to train and poorly interpretable. An alternative approach is rule-based methods using sentiment lexicons. They are fast, require no training, and are well interpreted. But recently, due to the widespread use of deep learning, lexicon-based methods have receded into the background. The purpose of the article is to study the performance of the SO-CAL and SentiStrength lexicon-based methods, adapted for the Russian language. We have tested these methods, as well as the RuBERT neural network model, on 16 text corpora and have analyzed their results. RuBERT outperforms both lexicon-based methods on average, but SO-CAL surpasses RuBERT for four corpora out of 16.