 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Scene Characteristics and Multi-Stream Convolutional Architectures in a Contextual Approach for Video-Based Visual Emotion Recognition in the Wild
Paper and Code
May 16, 2021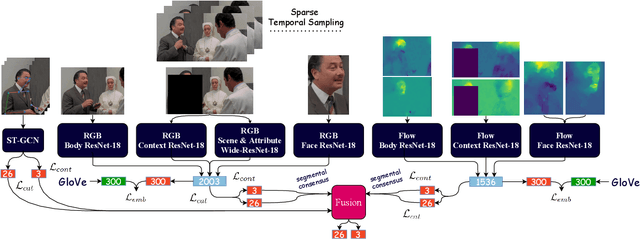



In this work we tackle the task of video-based visual emotion recognition in the wild. Standard methodologies that rely solely on the extraction of bodily and facial features often fall short of accurate emotion prediction in cases where the aforementioned sources of affective information are inaccessible due to head/body orientation, low resolution and poor illumination. We aspire to alleviate this problem by leveraging visual context in the form of scene characteristics and attributes, as part of a broader emotion recognition framework. Temporal Segment Networks (TSN) constitute the backbone of our proposed model. Apart from the RGB input modality, we make use of dense Optical Flow, following an intuitive multi-stream approach for a more effective encoding of motion. Furthermore, we shift our attention towards skeleton-based learning and leverage action-centric data as means of pre-training a Spatial-Temporal Graph Convolutional Network (ST-GCN) for the task of emotion recognition. Our extensive experiments on the challenging Body Language Dataset (BoLD) verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, by a large margin.