 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging human Domain Knowledge to model an empirical Reward function for a Reinforcement Learning problem
Paper and Code
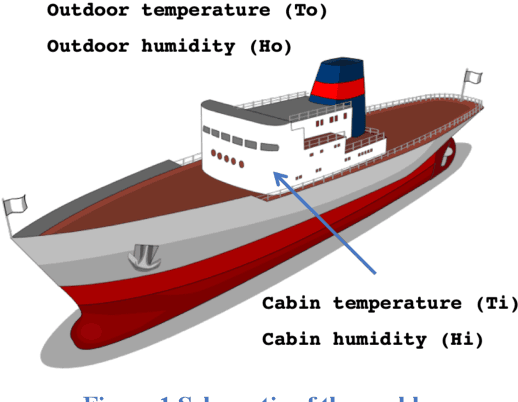
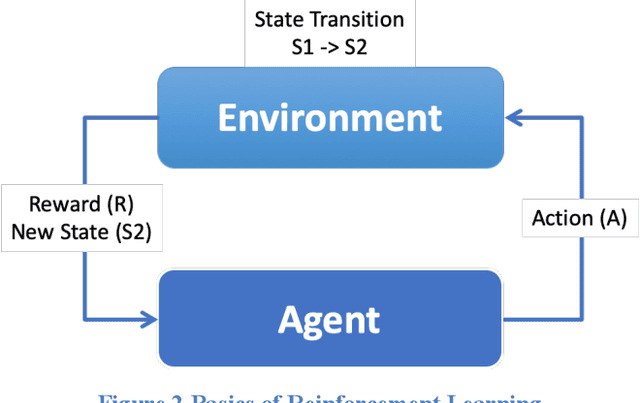
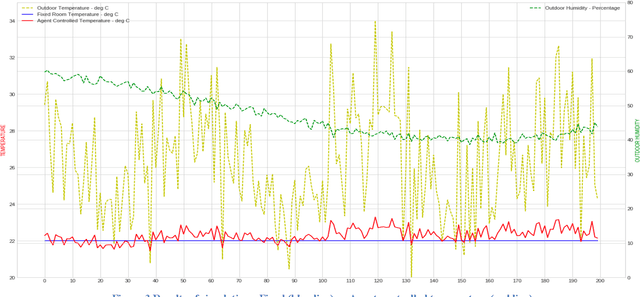
Traditional Reinforcement Learning (RL) problems depend on an exhaustive simulation environment that models real-world physics of the problem and trains the RL agent by observing this environment. In this paper, we present a novel approach to creating an environment by modeling the reward function based on empirical rules extracted from human domain knowledge of the system under study. Using this empirical rewards function, we will build an environment and train the agent. We will first create an environment that emulates the effect of setting cabin temperature through thermostat. This is typically done in RL problems by creating an exhaustive model of the system with detailed thermodynamic study. Instead, we propose an empirical approach to model the reward function based on human domain knowledge. We will document some rules of thumb that we usually exercise as humans while setting thermostat temperature and try and model these into our reward function. This modeling of empirical human domain rules into a reward function for RL is the unique aspect of this paper. This is a continuous action space problem and using deep deterministic policy gradient (DDPG) method, we will solve for maximizing the reward function. We will create a policy network that predicts optimal temperature setpoint given external temperature and humidity.